MongoDB: concetti fondamentali, architettura e comandi principali
Documento da Università su MongoDB. Il Pdf esplora i concetti fondamentali, l'architettura e i comandi principali di questo database NoSQL, con esempi pratici e diagrammi. Il documento, utile per studenti universitari di Informatica, copre replicazione e sharding, ed è stato prodotto con un'ottima qualità visiva.
Mostra di più18 pagine


Visualizza gratis il Pdf completo
Registrati per accedere all’intero documento e trasformarlo con l’AI.
Anteprima
INTRODUZIONE A MONGODB
Rimanendo sempre nei sistemi NoSQL vediamo nel dettaglio uno dei sistemi NOSQL: MongoDB.
Mongo lo possiamo trovare in due versioni: una server e una Atlas:
- Il mongodb server sono dei sistemi stand-alone che si possono scaricare e installare; esiste nella
versione free (communty ediction) che è la versione base, e poi esiste anche una versione
enterprise a cui vengono aggiunte alcune funzionalità. - Atlas, invece, è la versione pay-per-use, quindi un servizio che può essere utilizzato in cloud reso
disponibile su diversi cloud (Amazon AWS, MS Azure, Google Cloud, ecc ... ), è un managed database
(cioè la gestione del sistema del database viene offerta dal sistema cloud, quindi non abbiamo
bisogno di eseguire il setup e non abbiamo bisogno di preoccuparci di aggiornamenti della versione
di MongoDB; quindi tutta la gestione del DBMS viene demandata al sistema).
DIFFUSIONE DI MONGODB
Parliamo di MongoDB perché è tra i document database è quello che ha avuto la diffusione maggiore; il
merito va sicuramente al fatto che il modello a documento è molto intuitivo quanto il concetto di tabelle
(infatti è facile lavorare con i dati e visualizzarli) combinato con una buona progettazione del DBMS (perché
l'hanno costruito bene, cioè su basi solide) e quindi di conseguenza viene utilizzato in moltissime
applicazioni (es: Astrazeneca, Bosh, Adobe, Cisco, Splunk, ecc ... ). Chiaramente non viene utilizzato per
gestire il sistema informativo dell'azienda ma per gestire le applicazioni core offerte ai clienti.
CONCETTI BASE
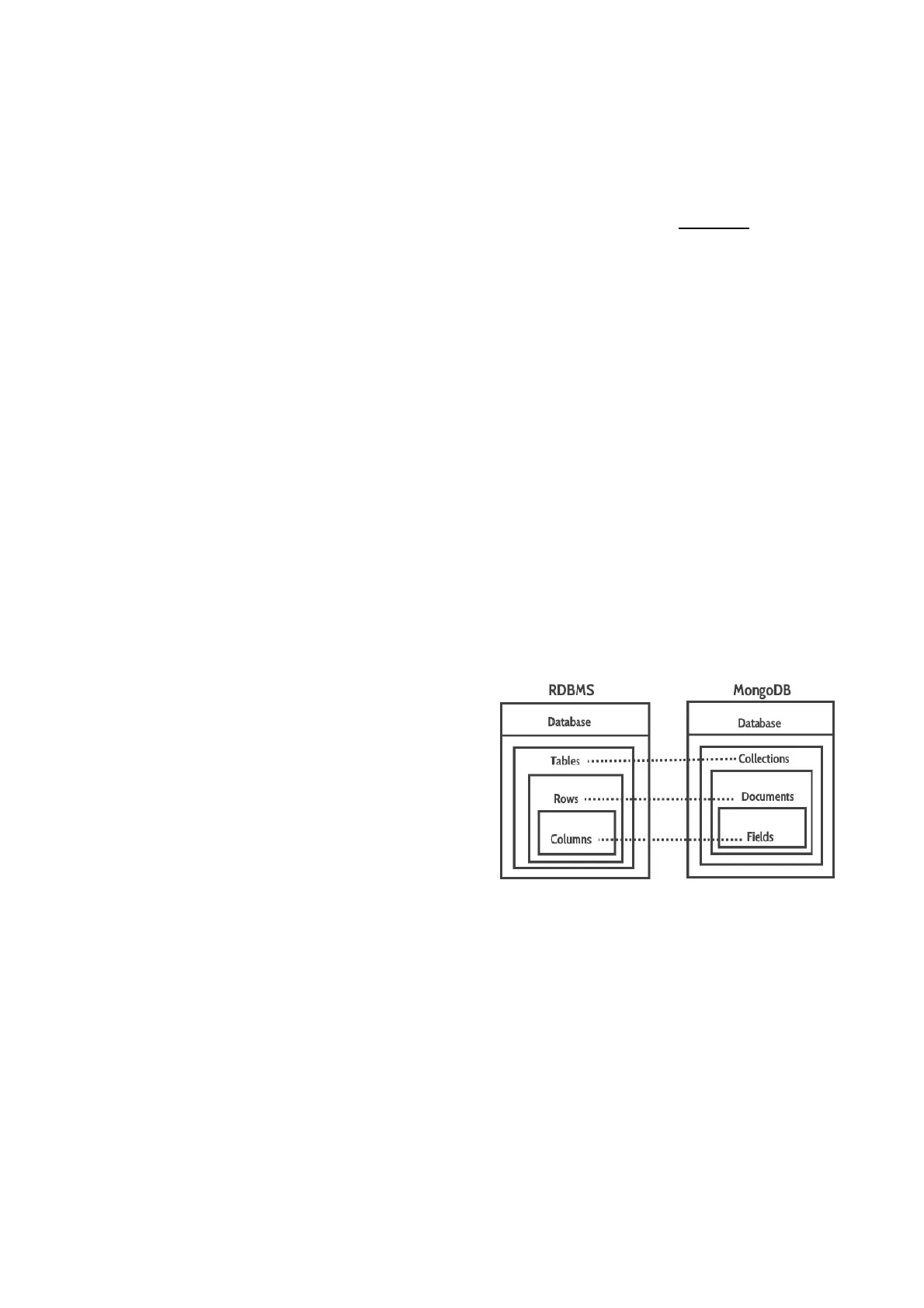
MongoDB gestisce i dati in forma di documenti, quindi
abbiamo un database che si compone in un insieme di
collezioni, le collezioni sono un insieme di documenti, i
documenti si compongono di campi o entry e quindi la
corrispondenza tra collezioni e tabelle di un RDBMS, tra
documenti e righe di una tabella e tra campi e colonne di
quella tabella.
RDBMS
MongoDB
Database
Database
Tables
.. Collections
Rows
Documents
Columns
Fields
Abbiamo già parlato della struttura di un documento e in
particolare abbiamo detto che MongoDB utilizza JSON; in verità utilizza una versione estesa di JSON che è
un JSON binario. Questo JSON binario, oltre che rappresentare i dati in formato binario all'interno di un file,
e quindi essere più efficiente, dà anche un supporto ulteriore come tipi per quelle che sono le date e i file
binari, cioè quelli che mi permettono di mantenere le immagini ad esempio, ed interessante è anche il
supporto per la geolocalizzazione degli elementi con un tipo "geo coordinate" che rende MongoDB anche
particolarmente utilizzato nei sistemi mobili laddove la localizzazione dell'utente è importante e cambia
con frequenza.
247Il documento MongoDB è un insieme,
{
first name: 'Paul',
surname: 'Miller' ,
String
Typed field values
quindi lo rappresentiamo come
cell: 447557505611,
Number
city: 'London' ,
Fields
location: [45.123,47.232],
Geo-Coordinates
Profession: [ 'banking', 'finance' , 'trader' ],
cars: [
elementi racchiusi tra parentesi graffe.
Ci sono coppie chiave valore dove la
Fields can contain
arrays
chiave è il nome dell'attributo e il
valore può avere diversi tipi: stringa,
{ model: 'Bentley' ,
year: 1973,
value: 100000, ... } ,
Laquo can contain an array of sub -
documents
intero, ecc ... Inoltre, come vediamo per
la chiave "Profession" c'è la possibilità
{ model: 'Rolls Royce',
year: 1965,
di campi composti in termini di array
value: 330000, ... }
(cioè una sequenza ordinata di
1
elementi che non devono essere per
forza omogenei: quindi posso avere un
array con stringhe e numeri ad esempio). Quindi l'idea è che questi elementi sono indicizzati non da una
chiave ma da una posizione all'interno dell'array e l'ordine è significativo. Nota: l'array viene anche
utilizzato per presentare le coordinate (come vediamo nell'immagine); il sistema, anche se è un array, è in
grado di riconoscere e trattare in maniera appropriata i numeri che rappresentano le coordinate latitudine
e longitudine di una certa posizione. Poi, ovviamente, l'array può essere formato anche da dati composti:
nell'esempio dell'immagine vediamo un array di macchine, che quindi rappresenta una lista di macchine
possedute da questa persona, in cui ogni macchina è rappresentata da una struttura.
ELEMENTI TECNICI SULL'ARCHITETTURA DEL DBMS: REPLICAZIONE E SHARDING
Replicazione
I vantaggi della replicazione li abbiamo detti tante volte. Chiaramente, dato che siamo in ambito NoSQL,
gestiamo dati replicati. I dati replicati vengono gestisti tramite degli oggetti che si chiamano replica set che
sono diverse istanze di MongoDB caricati all'interno di nodi differenti che contengono lo stesso dataset;
l'idea di replica set è una replicazione completa ma attenzione perché non è detto che questa replicazione
completa rappresenta l'intero database. Quindi i replica set sono insiemi di istanze MongoDB con lo stesso
dataset replicato. Nella replicazione, l'architettura prevede un numero dispari di nodi perché MongoDB
lavora con meccanismi di quorum, abbiamo un nodo tipicamente primario (quindi lavoriamo in un
meccanismo di replicazione di tipo master/slave) ed eventualmente può essere utilizzato un ulteriore nodo
arbitro che ha la funzione di mantenere il quorum in casi problematici (quindi l'arbitro non contiene dati
ma fa solo da gestore del mantenimento del quorum).
Per quanto riguarda i nodi, invece, per capire se i vari nodi sono vivi si inviano continuamente dei ping uno
con l'altro ogni 2 secondi (standard). Questo meccanismo permette di riconoscere l'eventuale caduta di un
nodo e quindi la ricostituzione del replica set in caso di errore.
CASO SENZA ARBITRO
Nel caso senza arbitro ho un'applicazione client che accede al
nodo primary sia per le scritture e sia per le letture. Le scritture
che arrivano al primary, quindi, vengono trasferite in maniera
asincrona ai secondary.
Finché tutto funziona bene non ci sono problemi; il problema è
gestire l'eventuale caduta di nodi ma ciò lo vedremo
direttamente nel sito http://thesecretlivesofdata.com/raft/.
Raft è un algoritmo di quorum per garantire l'atomicità. Più
precisamente Raft è un algoritmo di consenso distribuito; Raft,
Client Application
Driver
Writes
Reads
Primary
Replication
Replication
Secondary
Secondary
248quindi, serve per raggiungere il consenso per quanto riguarda le scritture e quindi, come abbiamo detto,
riguarda l'atomicità.
Immaginiamo di avere un singolo nodo che contiene un database MongoDB e, per semplicità, diciamo che
abbiamo un oggetto all'interno di questo database e un client (pallino verde) che spedisce certe
informazioni sul valore del nostro dato (quindi il client vuole aggiornare o aggiungere il valore 8 ad un
dato).
x
x
8
x
8
x
8
8
Nota: In questo caso con un nodo solo il consenso l'ho già raggiunto dato che ho una sola copia e quindi
quello è l'unico valore possibile per quel dato.
Domanda: che cosa succede se ho nodi multipli in cui voglio propagare l'aggiornamento?
Risposta: abbiamo 3 stati possibili che possono essere assunti dal nodo: follower, candidate, leader che
corrisponde all'elezione del primary.
Inizialmente tutti i nodi partono nello stato follower e il primo problema è quello di
eleggere il primary (oppure di rieleggere un primary in caso di caduta di un nodo).
Quindi, se i follower non ricevono segnale dal leader allora possono diventare
candidati di leader assumendo lo stato di candidato autonomamente e mandando
questo segnale (cioè questa loro volontà di diventare candidati leader) agli altri nodi
per richiedere i voti per diventare il leader. Se i nodi accettano allora il nodo diventa
leader.
Questo meccanismo è chiamato "leader election" che viene utilizzata o
all'inizializzazione del sistema o quando ci sono cadute dei nodi (in particolare del
leader).
Quindi il leader diventa il primary e il client parla con il leader.
5
Il leader si gestisce le modifiche all'interno di un log (node log) che
mantiene le modifiche effettuate sui propri dati. Non andiamo a modificare
il database; inizialmente, infatti, me li mantengono solo all'interno del log e
infatti non sono ancora in fase commit. Il leader, invece, va a replicare con
gli altri nodi trasferendo il valore sempre nel log e i follower mandano
indietro un messaggio di ackolodge.
2495
5
SET 5
SET 5
SET 5
Se il messaggio di acklonodge è ricevuto da una maggioranza dei nodi allora avviene il commit e quindi la
scritta da rossa diventa nera e significa che ho il commit e il dato lo posso andare a scrivere.
5
5
5
5
5
5
SET 5
SET 5
SET 5
SET 5
Quindi do la global decision ai nodi follower che anche loro vanno a rendere definitivo questo dato e quindi
ho raggiunto il consenso circa il valore del sistema. Qui usiamo una log replication nel senso che il dato non
viene immediatamente scritto ma le modifiche vengono riportate all'interno di un log che viene trasferito
all'interno dei diversi nodi.
Domanda: come faccio a decidere il leader per l'elezione? In che modo un nodo decide di candidarsi?
Risposta: ogni nodo ha un timeout allo scadere del quale vengono trasferiti le candidature.
Node B
Term: 0
Node A
Term: 0
Node C
Term:
0
Allo scadere del clock il nodo decide di proporsi
come candidato; ovviamente questi clock sono
randomizzati in modo da non avere delle
situazioni sincrone. Allo scadere di un timeout,
quindi, un nodo si candida:
Si vota spedendo le richieste di voto agli altri;
fatto questo gli altri resettano il loro clock di
election, rimandano indietro l'acknolodge e
Node B
Term: 0
Node A
Term: 1
Vote Count: 1
Node C
Term:
0
tengono l'informazione che c'è un nodo candidato (A in questo esempio).
Nel momento in cui il nodo diventa leader comincia a mandare dei messaggi periodici di heartbeat per
ascoltarsi l'un l'altro e garantire che i nodi siano vivi (senza guasti):
Node B
Term: 1
Voted For: A
Node A
Term: 1
Node C
Term: 1
Voted For: A
Dopodiché, ognuno risponde mandando indietro l'heartbeat (viene resettato a
0 un clock ad ogni messaggio di heartbeat). Quindi la rete è viva tutte le volte
che arriva il messaggio perché so che il leader sta funzionando.
250
Non hai trovato quello che cercavi?
Esplora altri argomenti nella Algor library o crea direttamente i tuoi materiali con l’AI.
