Statistica: ripasso dei concetti fondamentali e regressione statistica
Documento universitario sulla statistica ripasso. Il Pdf offre un ripasso conciso dei concetti fondamentali della statistica, distinguendo tra statistica descrittiva e inferenziale, con formule e grafici esplicativi per la Matematica a livello universitario, includendo accettazione e rifiuto delle ipotesi e regressione statistica.
Mostra di più67 pagine


Visualizza gratis il Pdf completo
Registrati per accedere all’intero documento e trasformarlo con l’AI.
Anteprima
Statistica: Ripasso Generale
STATISTICA RIPASSO
La statistica si divide in:
- Descrittiva > capisce per ogni variabile il livello di misurazione (differenzia quindi tra
variabili quantitative e qualitative). Si affida alla distribuzione di tipo normale conoscendo media e
deviazione standard (in questo modo le variabili acquisiscono un significato). Utilizza:
- le scale di misura (nominale, ordinale, a intervalli equivalenti, a rapporti equivalenti),
- gli indici a tendenza centrale (moda, media e mediana)
- indici di dispersione (nº di categorie, indice di omogeneità, distanza interquartilica, coefficiente di variazione CV =_ DS .100 campo/intervallo di variazione VALORE MAX - VALORE MIN = SSM [scarto semplice medio] >ilxi -XI SSM = N VARIANZA = Z (xi-x) -12 varianza deviazione standard SD=7 N
Scale di Misura e Indici
scala nominale-> moda e nº di categorie scala ordinale > mediana e distanza interquartilica scale a intervalli e a rapporti equivalenti > media, campo di variazione, coefficiente di variazione SSM, varianza e DS.
Statistica Descrittiva: Suddivisioni
(statistica descrittiva) Si divide in:
- univariata (serve a descrivere una variabile)
- bivariata (serve a descrivere il rapporto tra due variabili)
- multivariata (serve a descrivere il rapporto tra più variabili)
E (Xi-x)2 N
- Inferenziale -> parte della statistica che, a partire dalle informazioni su un campione, vuole avere informazioni sulla popolazione; oppure che, a partire da alcune informazioni raccolte su un campione, vuole verificare un'ipotesi. Quindi si occupa della verifica di ipotesi e della stima di parametri sulla popolazione. (parte dal concetto centrale di probabilità). 1Quindi serve per STIMARE (conoscere in maniera indiretta) un parametro (sarebbe l'indagine sulla popolazione) a partire da un indicatore (sarebbe l'indagine sul campione)-> Stimiamo l'errore in ciò che abbiamo fatto nella descrittiva.
Accettazione e Rifiuto Ipotesi
Ipotesi H0 e H1
ACCETTAZIONE E RIFIUTO IPOTESI H0: la realtà funziona in termini di casualità = a quella di una distribuzione normale H1: si basa sul fatto che ci sia stato un evento che fugge al caso (ad esempio un addestramento/apprendimento).
Significatività Alpha
Alpha: secondo la teoria supporta H1, sarebbe la significatività, margine di errore che togliamo al caso. Per il 5% non attribuiamo al caso dato che sono rari, ipotizzo che c'è un qualcosa che è intervenuto.
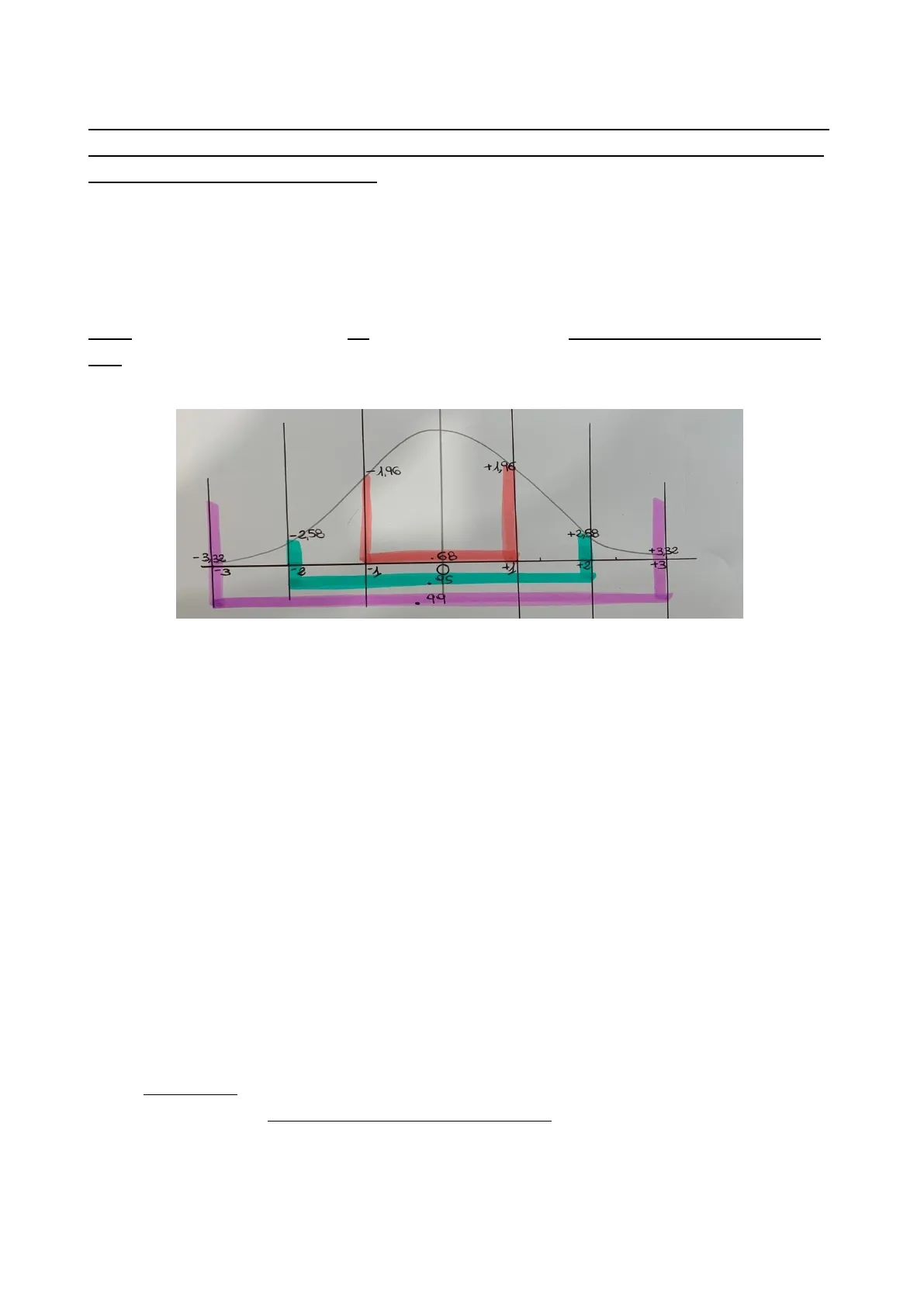
+1,96 -1,96 -2,58 +2,88 +3,32 00 3/32 . 68 +3 3 -2 -1 99
Curva Normale e Z Critico
- l'area sottesa alla curva è uguale a 1 (l'area compresa tra - e la media è uguale a .50; l'area compresa tra la media e + è uguale a .50)
- qualunque siano i valori della media e della DS, l'area corrispondente a intervalli definiti è sempre la stessa = u ±10₴ .68 (P = 0,05) > Z critico bidirezionale = +/- 1,96 u ±20~ . 95 (P = 0,01) -> Z critico bidirezionale = +/- 2,58 u ±30~ . 99 (P = 0,001) >Z critico bidirezionale = +/- 3,32
- Code più piccole significa che il punteggio di Z è superiore a 3 e quindi rifiuto H0;
- Code più grandi vuol dire che Z è compreso tra 0-3 e quindi accetto H0. (se so quanto è grande la coda o il punto Z posso calcolare se accettare o menoH0).
Trattamento Preliminare dei Dati
(in generale) -> La statistica viene utilizzata per analizzare il set di dati. Il primo passaggio prevede il trattamento preliminare (detto così perché viene prima dell'analisi statistica vera e propria). Attraverso questo passaggio андiamo a considerare se i dati raccolti sono utilizzabili o no. Una volta capito questo, bisogna considerare quali tecniche statistiche possono essere utilizzate. Da qui infatti possiamo dividere la statistica in:
- Parametrica (riguarda la possibilità di calcolare indici di dispersione come la media e la deviazione standard > deve essere una distruzione normale. Dunque risponde alle domande "la distribuzione è a intervalli?" "Posso calcolare la media?" (Se la risposta a questi quesiti è si, allora si può usare la statistica parametrica) 2
Statistica Non Parametrica
1• Non parametrica (no distribuzione normale e quindi no media e DS ma ranghi, mediana, la moda, .... ). si usa inoltre per campioni molto piccoli e per scale ordinali e nominali ( ci permettono di capire solo se un valore è superiore all'altro).
Confronto Parametrica e Non Parametrica
Perché ci poniamo questo problema? Perché essenzialmente la statistica parametrica è la più potente: ci permette di conoscere la realtà in termini probabilistici ma con più precisione rispetto alla non parametrica.
Operazioni Statistiche
Una volta scelta la statistica con la quale operare, effettuiamo una serie di operazioni, come:
- la regressione (ha come obiettivo quello di capire la relazione tra variabili)
- l'analisi fattoriale (ha un duplice obiettivo: ridurre la complessità dei dati, ossia capire come alcune variabili sono simili tra loro e metterle insieme; trovare le strutture latenti non osservabili - capire cioè quali sono le dimensioni e i punteggi da calcolare nei test psicologici).
Componente Vera e Componente di Errore
Durante queste operazioni si rileva costantemente una componente vera e una componente di errore. Abbiamo due tipi di errore:
- errore sistematico (è sempre lo stesso, è costante, che non si basa sul caso ma che addirittura potrebbe passare inosservato. Non si elimina ma si cerca di controllare all'interno del concetto di validità. Se interviene deve essere tutto buttato)
- errore casuale (errore che può in più o in meno capitare - ossia un errore che sovrastima o sottostima la quantità corretta - es. se misuro una persona col metro alle volte dico che ha un cm in più altre volte in meno, quindi sappiamo che se prendo un valore centrale, l'errore possibile è in + e in - . In più possiamo dire che gli errori grandi sono meno comuni di quelli piccoli. Dunque l'errore casuale funziona secondo una distribuzione normale, cioè gli errori hanno una probabilità di osservarsi in base alla loro grandezza. Quindi l'errore causale ha un pattern, cioè cambia solo in base al caso, e per questo può essere controllato tramite la statistica: cambiando ci fa vedere che c'è un errore, ma avendo un pattern costante probabilistico può essere corretto tramite la probabilità, all'interno del concetto di affidabilità).
Attendibilità dei Test Psicologici
3ATTENDIBILITA' un test psicologico è attendibile se è in grado di fornire valutazioni stabili e coerenti, ossia deve sempre dare lo stesso risultato in qualunque momento sia utilizzato e da chiunque sia utilizzato (ci deve dunque essere una generalità nel tempo e nei soggetti. Quest'ultimo punto è importante per i test eterovalutati, come l'intervista semi-strutturata, dato che lo psicologo fa le domande e la persona risponde in termini narrativi. Lo psicologo deve cioè estrarre da queste narrazioni la variabile, ossia deve indicare se è presente o assente. Ad esempio, intervista sulla depressione - dobbiamo valutare la tristezza: il clinico deve attribuire il punteggio a quella caratteristica psicologica. Ha senso dunque che chiunque somministri quel test debba ottenere lo stesso risultato).
Modelli Matematici dell'Attendibilità
Il punteggio ottenuto da un individuo in un test può essere considerato però come costituito da una componente vera e da una di errore. Questa equivalenza può essere espressa in termini di devianza (modelli matematici della misurazione):
CT = Cv +( Ce Devianza delle componenti false, comprende l'errore casuale (che può variare da - infinito a + infinito).
Il rapporto Cv / Ct esprime la proporzione di variabilità vera rispetto alla variabilità totale. Questo rapporto corrisponde al modello matematico teorico dell'attendibilità:
rxx = S2v / S2t > coefficiente di attendibilità, si utilizza il coefficiente di correlazione (r) e si misura la stessa variabile per due volte (xx) = è sufficiente somministrare lo stesso questionario per due volte.
Grazie a questo modello, metto a confronto quanto è grande l'errore rispetto la componente vera. Il coefficiente ha punteggio tra 0 e +1, se è uguale a 0 allora vuol dire che S2v è 0 (ossia la componente d'errore è massima e allora non c'è attendibilità); viceversa, se il punteggio è 1 allora vuol dire che c'è massima attendibilità.
Perciò il punteggio che un soggetto ottiene a un test non è il suo punteggio reale perché formato sia dalla componente vera che quella di errore. Il reale punteggio si distribuisce tra due intervalli di confidenza di valori possibili. Più l'attendibilità è alta, minori sono gli intervalli di confidenza e viceversa.
Procedimenti di Stima dell'Attendibilità
Inoltre, l'indice di attendibilità di un test psicologico può essere stimato sui dati campionari attraverso 4 procedimenti (che prevedono il calcolo del coefficiente di correlazione):
- Attendibilità test - retest, consiste nella somministrazione di un test psicologico ad uno stesso campione in due momenti successivi. In tal modo posso rilevare la correlazione tra i punteggi ottenuti dai soggetti durante la prima e la seconda somministrazione. Questo procedimento mi da indicazioni riguardo la stabilità di uno strumento (l'errore si avrebbe nella non corrispondenza tra i punteggi).
Es. se l'attendibilità test-retest di uno strumento di valutazione quantitativa di una caratteristica psicologica è pari a 0.80 (r) vorrà dire che il 64% (0.802 "r2") delle differenze tra i punteggi ottenuti nelle due somministrazioni sono attribuibili a differenze reali, mentre il restante 36% (1-r2) delle differenze sono attribuibili ad errori di misurazione.
- Attendibilità per forme parallele, consiste nel rilevare la correlazione dei punteggi ottenuti dagli stessi soggetti in due test simili (ossia che si riferiscono alla stessa caratteristica/variabile, ma 4con differenti item). La somministrazione può avvenire in tempi diversi o nella stessa seduta. Questo tipo di coefficiente esprime il grado di equivalenza delle due forme del test e rispetto al precedente fa sì che non ci sia apprendimento o abitazione rispetto ai contenuti degli item (è però difficile creare due varianti dello stesso test, ne esistono pochissimi casi). Un esempio sono le tavole di Rorschach.
- Divisione a metà (split half), consiste nel correlare i punteggi ottenuti da un gruppo di soggetti in due raggruppamenti di item dello stesso test psicologico. La suddivisione che si preferisce è tra i numeri pari e quelli dispari, in quanto una suddivisione tra la prima metà e la seconda metà del test potrebbe risentire di una caduta di prestazione dovuta dalla stanchezza, dalla mancata motivazione, ... che si osserva nella parte finale di una seduta di somministrazione. Questo tipo di coefficiente ci da indicazioni sull'omogeneità degli item che compongono il test. Bisogna ricordare che dividendo gli item di un test, è come se stessimo calcolando due test più piccoli. Per recuperare la lunghezza originale, si utilizza la formula profetica di Spearman - Brown - Rkk = kr / 1+(k-1)r Rkk: coefficiente di attendibilità r: correlazione media tra gli item k: numero degli item Dalla formula di Spearman si può derivare una formula per valutare di quante volte deve essere allungato un test per ottenere un certo coefficiente di attendibilità: n = r(1-r') r'(1 -r) n : numero di volte che il test deve essere allungato r' : coefficiente di attendibilità del test originario r : coefficiente di attendibilità desiderato
- Intercorrelazione multipla tra tutti gli item, riguarda la coerenza interna del test (omogeneità
di contenuto). Per questo procedimento si possono utilizzare:
- se gli item prevedono risposte alternative l'indice alpha di Cronbach (un test dovrebbe avere almeno uno 0,70 di attendibilità per essere utilizzato, anche se autori più recenti sostengono che dovrebbe arrivare a 0,95 -STANDARD DI ATTENDIBILITA') k a = k-1 M Sx ,2 a = coefficiente di attendibilità, k = numero degli item del test, Sx2 = varianza dei punteggi totali ottenuti da ciascun soggetto nel test, Esj2 = sommatoria delle varianze di tutti i suoi item.
- se gli item sono dicotomici, l'indice di Kuder - Richardson 20. 1xx = k-1 k 1- 7 _2 Sx k = numero degli item, pj = proporzione di risposte di una categoria all'item, qj = proporzione di risposte dell'altra categoria all'item, Sx2 = varianza dei punteggi totali ottenuti da ciascun soggetto nel test. 5
Non hai trovato quello che cercavi?
Esplora altri argomenti nella Algor library o crea direttamente i tuoi materiali con l’AI.
