Codice Unicode: sistemi di codifica e memorizzazione dati nella RAM
Slide di Università sul Codice Unicode. Il Pdf esplora i concetti di codici digitali pesati e le diverse possibilità di memorizzazione dei dati nella RAM, come big-endian e little-endian, per la materia Informatica.
Mostra di più16 pagine


Visualizza gratis il Pdf completo
Registrati per accedere all’intero documento e trasformarlo con l’AI.
Anteprima
Stringhe di bit
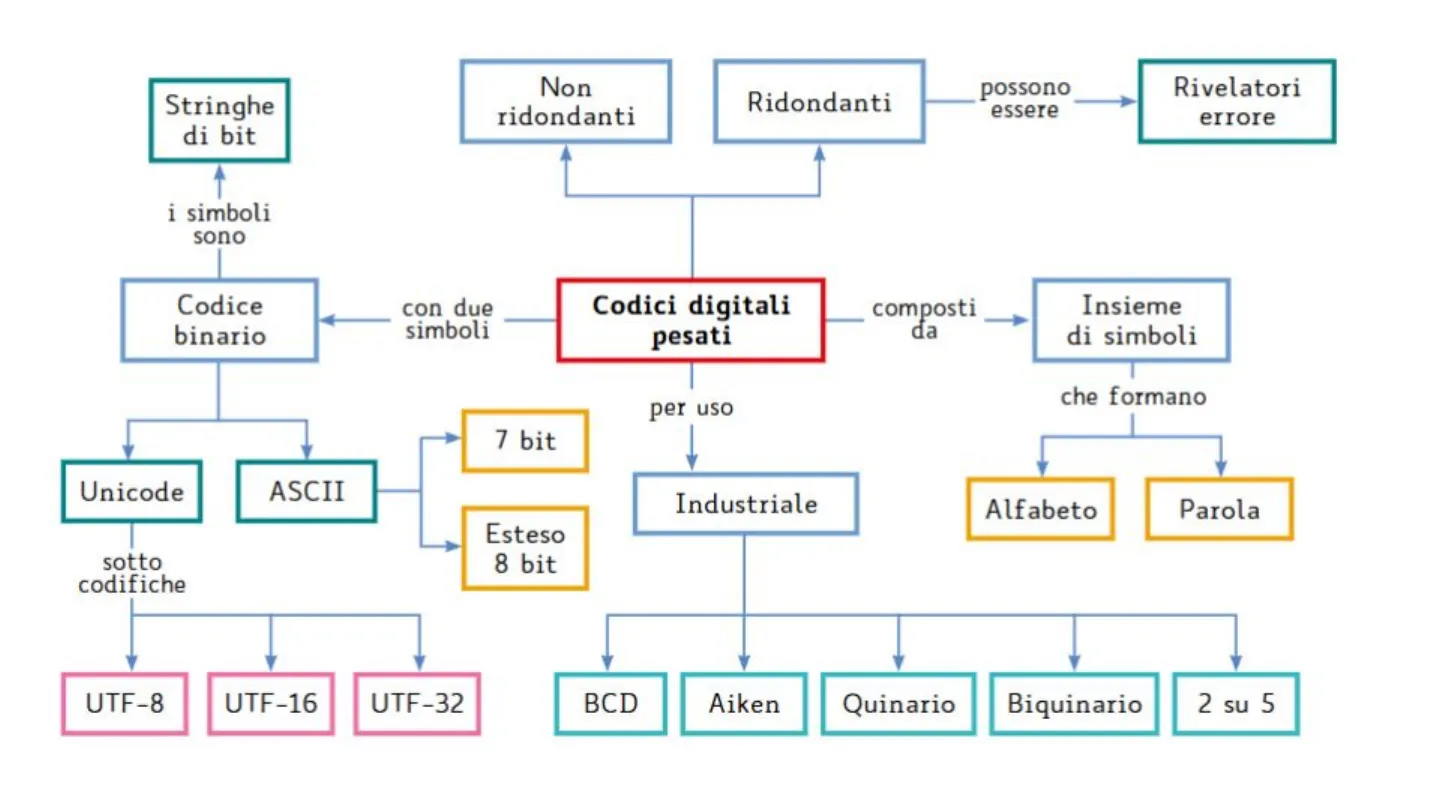
Non ridondanti Ridondanti possono essere Rivelatori errore i simboli sono Codice binario con due simboli Codici digitali pesati composti da Insieme di simboli che formano per uso 7 bit Unicode ASCII Industriale Alfabeto Parola Esteso 8 bit sotto codifiche UTF-8 UTF-16 UTF-32 BCD Aiken Quinario Biquinario 2 su 5E Simbolo × Simboli Caratteri speciali Carattere: (testo normale) V Sottoinsieme: Punteggiatura generale V , - 11 + . . ... , %0 1 0 i 4 5 6 7 8 9 + - = ()n 0 1 2 3 4 5 6 7 8 I 9 + - = () a ℮ o X ℮ | h - m n p S Simboli usati di recente: . € E ¥ O ® TM +1 VI AI X 8 3 2 Nome Unicode: Codice carattere: 2022 da: Unicode (hex) > Bullet Unicode (hex) Correzione automatica ... Tasti di scelta rapida ... Tasti di scelta rapida: ALT+0149 ASCII (decimale) ASCII (hex) Inserisci - 1 ...
Il Codice Unicode
Con 256 configurazioni l'ASCII è sufficiente per gli alfabeti dell'Europa occidentale e del Nord America, ma limitato per la rappresentazione di alcuni caratteri e simboli. Quindi si è passati all'UNICODE, cioè un codice a 16 bit (216 = 65 536 configurazioni) per cercare di soddisfare tutte le esigenze. Nella versione più estesa dell'Unicode ogni simbolo viene rappresentato attraverso una codifica a 32 bit. In Unicode un simbolo prende il nome di codepoint e viene descritto con la notazione "U+numero esadecimale". Un codepoint assume valori da U+0x00000000 a U+0xFFFFFFFFplane 01 02 03 0-4 05 06 07 09 OA 08 OC OD DE OF Latin script 10 11 12 13 14 15 15 17 18 19 LA 18 1 1D 1E 1F Non-Latin European scripts 21 22 23 24 25 26 27 28 29 2A 28 20 2E 2F 30 31 32 33 34 35 36 37 38 39 38 3C 3D 3E 3F 40 41 42 43 44 45 46 47 48 49 4,4 48 4C 4D 4E 4F 50 51 52 53 54 55 56 57 58 59 58 5C 5D 5E 5F 60 61 62 63 6.4 65 66 67 68 69 68 GC 6D 6E 6F 70 71 72 73 74 75 76 77 78 79 78 7C 7D 7E 7F CJK characters 81 82 83 84 85 86 87 88 89 88 BD BE BF Indonesian and Oceanic scripts 90 91 92 93 94 95 96 97 98 99 98 9C 90 SE 9F AD A1 A2 A3 A4 A7 AA AC AD KE AF Notational systems 80 BI 87 83 84 85 B6 B17 88 89 BA BB BC BE BF Symbols Co CI C2 C3 C4 C5 C6 C7 C8 c9 CA CB CC LCD CE CF DO DI D2 D3 D4 05 D6 D7 E7 E8 E9 EA EB EC ED EE EF FO F1 F2 F3 F4 F5 F6 F7 F8 F9 FA FB FC FD FE FF As of Unicode 9.0 Unallocated code points EO EI E2 E3 E4 E5 E5 African scripts Middle Eastern and Southwest Asian scripts South and Central Asian scripts Southeast Asian scripts East Asian scripts American scripts Private use UTF-16 surrogates DB D9 DA DB DC DD DE DFplane (17)UTF L'insieme dei caratteri così ottenuti si chiama UCS (Universal Character Set). Sono state definite tre sottocodifiche, chiamate codifiche UTF (UCS Transformation Format), al fine di ottimizzare la memorizzazione, la comunicazione e l'interpretazione da parte dei dispositivi.
- UTF-8 è una codifica a lunghezza variabile particolarmente usata nelle comunicazioni come, per esempio, la produzione di pagine web.
- UTF-16 è una codifica a lunghezza variabile spesso usata nelle elaborazioni applicative, come Java, che la utilizza come sua codifica interna.
- UTF-32 è una codifica a lunghezza fissa di 4 byte poco usata perché porta a un notevole impiego di memoria.
Codifica UTF-8
La sottocodifica Unicode UTF-8 è a lunghezza variabile: utilizza da 1 a 4 byte.
- I primi 27 = 128 codepoint sono codificati con 1 byte e corrispondono uno-a-uno con i 128 caratteri ASCII, mantenendo quindi la validità del codice ASCII in questa codifica.
- I successivi codepoint fino a 211 (per un totale di altri 1920 caratteri) sono codificati con 2 byte e coprono tutti i caratteri delle varie estensioni ASCII.
- I successivi codepoint fino a 216 (per un totale di altri 63 488 caratteri) sono codificati con 3 byte.
- I successivi codepoint sono codificati con 4 byte.
Struttura della codifica UTF-8
La struttura della codifica è illustrata di seguito.
- Il bit più significativo dei codici a 1 byte solo è sempre 0.
- I codici a più di 1 byte sono costituiti da sequenze di byte lunghe da 2 a 4 byte, composte da un byte iniziale di definizione e da uno o più byte di continuazione:
- il byte di definizione inizia con una sequenza di 1 pari al numero di byte totali della codifica; questa sequenza termina con uno 0;
- i byte di continuazione iniziano con la sequenza fissa 10, utilizzata per verifiche di correttezza.
Range caratteri Unicode e codifica UTF-8
CODIFICA UTF-8 RANGE CARATTERI UNICODE CODE POINT (IN BINARIO) CODIFICA UTF-8 (IN BINARIO) NOTE 000000-00007F 128 caratteri OZZZZZZZ sette bit z OZZZZZZZ sette bit z Range equivalente all'ASCII (inizia O). 000080-0007FF 1920 caratteri 00000yyy yyzzzzzz tre bit y; due bit y, sei bit z 110yyyyy 10zzzzzz cinque bit y, sei bit z Primo byte inizia 110, secondo 10. 000800-00FFFF 63488 caratteri xxxxyyyy yyzzzzzz 4 bit x, 4 bit y; 2 bit y, 6 bit z 1110xxxx 10yyyyyy 10zzzzzz quattro bit x; sei bit y; sei bit z Primo byte inizia 1110, gli altri 10. 010000-10FFFF 1048576 caratteri 000wwwxx xxxxyyyy yyzzzzzz 3 bit w, 2 bit x; 4 bit x, 4 bit y; 2 bit y, 6 bit z 11110www 10xxxxxx 10yyyyyy 10zzzzzz tre bit w; sei bit x; sei bit y; sei bit z Primo byte inizia 11110, gli altri 10.
Memorizzazione dei dati nella RAM
La memoria RAM di un elaboratore è divisa in unità (locazioni) e ogni indirizzo individua un'unità di locazione:
- la locazione ha dimensione standard di 8 bit, cioè 1 byte;
- l'indirizzo ha come dimensione usuale 32 bit, quindi 4 byte.
Dato che i calcolatori operano su parole di 32-64 bit (4-8 byte), esistono due possibilità per memorizzare una parola composta da più byte distribuendo questi ultimi su un gruppo di locazioni da 1 byte contigue:
- big-endian (BE), il primo byte della parola viene collocato nella locazione con indirizzo più basso e la fine della parola viene scritta negli indirizzi più alti;
- little-endian (LE), il primo byte della parola viene collocato nella locazione con indirizzo più alto e la fine della parola viene scritta negli indirizzi più bassi.
Esempio di memorizzazione dei dati nella RAM
Inseriamo la parola "AB C2 EF 03" nei byte con indirizzi da 4 a 7:
Register BIG-ENDIAN LITTLE-ENDIAN ABC2EF03 76543210 Memory Memory ABC2EF03 76543210 4 -> AB (10101011)2 4->03(00000011)2 03 1 0 7 7 76 EF 6 6 C2 57 C2 EF 5 5 AB 16 4 4 03 1 0 7 -03 (00000011)2 7 -> AB (10101011)2 big-endian little-endian AB 5 -> C2 (11000010)2 5 - EF (11101111)2 6 - EF (11101111)2 6 - C2 (11000010)2 Register
Codifica UTF-16
Anche la codifica UTF-16 è a lunghezza variabile e codifica i codepoint del set di caratteri Unicode utilizzando da 1 o 4 byte: è comunemente utilizzata nei sistemi operativi, in alcuni linguaggi (per esempio Java) e nelle applicazioni in sostituzione delle codepage. In UTF-16 lo spazio di codice Unicode è diviso in diciassette "piani" di 216 (65 536) codepoint ciascuno, con i codepoint di ogni piano che hanno valori esadecimali da xx0000 a xxFFFF, dove xx è un valore esadecimale 00-10 che indica il piano di appartenenza, mentre la parte rimanente si ripete in piani diversi.
Svantaggi della codifica UTF-16
Il principale svantaggio della codifica UTF-16 è di avere, rispetto a UTF-8, una quantità di bit di codifica maggiore a parità di quantità di informazione. È inoltre necessario inserire prima di un testo UTF-16 una sequenza che consenta di riconoscere quale disposizione è stata adottata per l'ordine di memorizzazione dei byte, cioè little-endian(LE) o big-Endian (BE).
Codifica UTF-32
A differenza delle due codifiche descritte in precedenza, che utilizzano la codifica a lunghezza variabilei, UTF-32 è una codifica a lunghezza fissa di 4 byte in cui i codici dei caratteri corrispondono ai codici UCS ("Universal Character Set" e corrisponde ad un vastissimo repertorio di caratteri) e che, quindi, consente la contemporanea rappresentazione dei codici di tutte le lingue. Anche nella UTF-32 sono possibili le due codifiche little-endian e big-endian. Anche se comporta un notevole impiego di memoria, viene usata molto frequentemente per la sua comodità di interpretazione nelle strutture interne di un sistema operativo e nella memorizzazione dei dati; infatti non richiede algoritmi di interpretazione perché tutti i caratteri UCS sono direttamente rappresentati. La codifica UTF-32 non viene mai usata nelle comunicazioni Internet.
studiare da pag. 132 a pag.136
Non hai trovato quello che cercavi?
Esplora altri argomenti nella Algor library o crea direttamente i tuoi materiali con l’AI.
