NLP Intro: Natural Language Processing, traditional and deep learning approaches
Slides about NLP Intro, Natural Language Processing. The Pdf provides an introduction to Natural Language Processing (NLP), distinguishing between traditional and deep learning approaches. It covers applications, text analysis techniques like n-grams and Bag of Words, and text units such as characters, words, and sentences, suitable for university computer science students.
See more24 Pages


Unlock the full PDF for free
Sign up to get full access to the document and start transforming it with AI.
Preview
What is Natural Language Processing?
Natural Language Processing is a subfield of artificial intelligence that deals with the interaction between computers and human language, focusing on understanding, generating and interpretating language. You might also come across the term text mining as another name for NLP. So, in this field, a computer must do two main things: . Understand human language (Natural Language Understanding - NLU or Natural Language Interpretation - NLI): thanks to transformers and similar models, systems have become highly effective at understanding. • Generate content in human language (Natural Language Generation - NLG), which means creating new text. This is more related to Large Language Model The goal is to develop systems that are both effective (in terms of accuracy and quality) and efficient (in terms of speed and resources).
Distinction between Traditional and Deep Natural Language Processing
Traditional NLP relies on linguistic rules and models, often using tools like parsers to analyze syntax, but it doesn't involve learning from data - there's no machine learning or deep learning for tasks like classification or generation. Deep NLP, on the other hand, are data-driven models that leverage machine learning, especially neural networks, to learn patterns directly from large datasets.
Deep NLP Techniques and Machine Learning
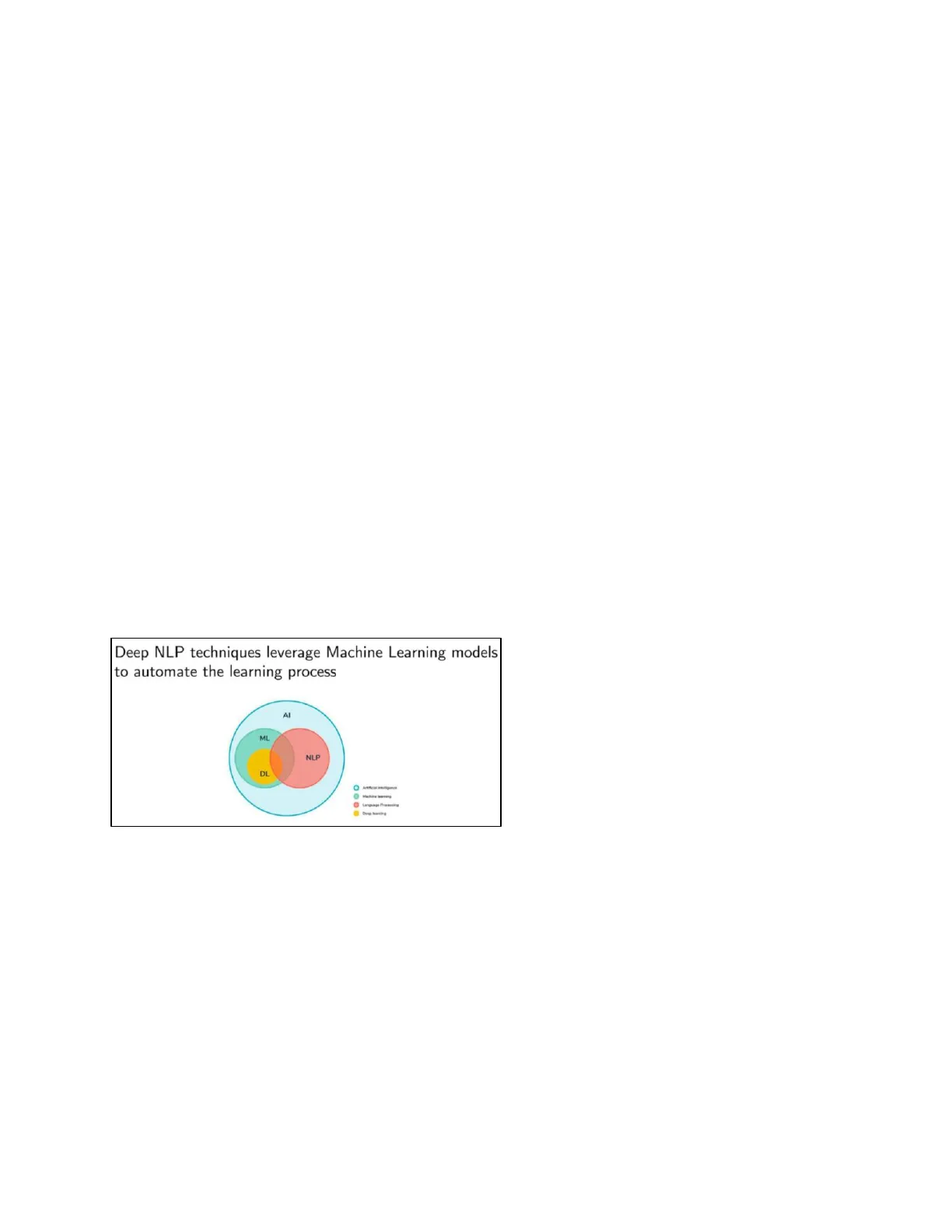
Deep NLP techniques leverage Machine Learning models to automate the learning process Al ML NLP Deep learning is a subset of machine learning based on multi-layer neural networks. Deep NLP fits into this framework, but classical NLP refers to older approaches that don't use machine learning or deep learning. Deep learning isn't always ideal - especially in DL domains like law, where expert, domain-specific understanding is crucial. General-purpose language models may misinterpret legal texts if they haven't been fine-tuned, as they lack the specialized knowledge needed. This is why we often need to combine solutions from different fields. Traditional NLP involves building manual knowledge bases - like dictionaries or syntactic rules - to detect patterns, styles, or even the language of a text. These rule-based systems can be highly accurate, but only within narrow, controlled domains. Their main limitation is lack of flexibility. They require constant human maintenance, and often don't transfer well to new domains, where vocabulary and context may change - even the same word can have different meanings. Deep learning, instead, focuses on models that learn from data. They infer relationships and patterns from large corpora - capturing semantic and syntactic structures without expert intervention. Human input is used to fine-tune, not define, the model.
Types of Data for Traditional and Deep Natural Language Processing
It's important to distinguish between different types of data. Traditional applications often deal with structured data - as census data or classical databases - where each feature - like names or birthdates - is clearly defined and limited to specific values. Language is constantly evolving, with new words, varying styles depending on the context - social media vs. academic writing, for example. That's why NLP mainly deals with unstructured or semi-structured data. Semi-structured text might have paragraphs or sections that give some context, but it still lacks the fixed format of structured data like relational tables.
Related buzzword: text mining
So, in general text mining is the process of deriving significant information from text, while NLU (or NLI) is a subtopic of NLP that deals with machine reading comprehension using AI techniques. For example, if I give you a document and you must train a classifier to assign it a label based on its topic (whether it's about sports, economics, politics, etc.) - is this understanding or generation? It is understanding, because you don't have to generate anything. The classification labels are already defined a priori, and your task is to understand the meaning of the text and assign the most likely label. You are simply interpreting the content and deciding based on that understanding. When you need to produce text - like translating, summarizing, or paraphrasing - you're performing generation. In these cases, the system must usually combine understanding (of the input) with generation (of the output). You don't generate text at random; it's always conditional on the input.
Overview Of NLP Applications
NLP techniques are widely applied in knowledge discovery and decision support systems, often serving as a crucial part of the data science pipeline. We will focus on the following subfields:
- Sentiment Analysis
- Text Categorization
- Machine Translation
- Question Answering
- Topic Modeling
- Text Summarization
Sentiment Analysis
We'll start with sentiment analysis, also called opinion mining. The goal is to extract feelings, emotions, or opinions from text. For example, by analyzing a social media post, we can infer the sentiment from features like word choice, structure, or punctuation - exclamation marks might suggest anger, happiness, or excitement. This task overlaps with emotion recognition and feeling detection.
- Extract writer's feeling, opinion, emotions, likes/dislikes o Also known as opinion mining
- Identify the opinion/human behavior of a person from plain text
- It can rely either on traditional NLP rules or on Machine Learning "I am happy with this water bottle." Positive "This is a bad investment." Negative "I am going to walk today." Neutral Traditionally, sentiment analysis distinguishes between positive and negative opinions - what someone likes vs. dislikes. There's also a neutral category for cases where the sentiment is unclear or mixed. This is usually treated as a classification problem, where the model assigns a label - positive, neutral, or negative - from a predefined set. More advanced models go beyond this. They might assign a numerical score (e.g., from 0 to 1) to represent sentiment intensity, or give separate scores for each class. Classification is generally easier and more accurate, but regression offers more nuanced insights. There's no one-size-fits-all solution - the right choice depends on the specific context.
Sentiment Analysis Use Cases
Sentiment analysis can be applied in many contexts to extract valuable insights from textual data. For example, if we collect customer reviews from a hotel booking platform, we can analyze the text to determine whether a guest was satisfied or not. Rather than relying solely on overall sentiment, which might already be reflected in a numerical rating (e.g., 9 out of 10), we can apply contextual sentiment analysis to identify sentiment related to specific aspects of the experience. Using natural language processing (NLP), we can infer separate sentiment scores for categories such as cleaning service, food quality, or sports facilities, even when these scores are not explicitly provided in the review. In finance, sentiment analysis is often used to process news articles or social media content, such as tweets, to detect key events that might influence stock prices. For instance, a positive reaction to a company's quarterly earnings report-especially if it exceeds expectations-can signal a potential price increase. Similarly, monitoring social media and user-generated content can be useful in marketing, customer support, and brand reputation analysis, where detecting public sentiment in real time helps companies respond effectively and make informed decisions.
Example of sentiment analyzer: VADER
- Input sentiment_analyzer_scores("The phone is super cool.")
- Output The phone is super cool --- {'neg': 0.0, 'neu':0.326, 'pos': 0.674, 'compound': 0.7351} There is a widely used library named VADER. This library is based on a traditional NLP approach - it relies mainly on expert-driven rules, and is not based on deep learning. VADER performs quite well in some general-purpose sentiment analysis scenarios. For instance, if you apply it to a simple sentence like "The phone is super cool", the system will return a sentiment score for each class - negative, neutral, and positive. In this example, the message is clearly positive, so the positive score is much higher than the negative one. VADER also provides a compound score, which is a combined overall score summarizing the sentiment.Its main strength is simplicity: it's fast, easy to use, doesn't require a GPU, and doesn't depend on large models. But the downside is its limited flexibility. Since it relies on manually defined rules, adapting it to new expressions or slang requires manual updates, which can be tedious and hard to maintain.
Text Categorization
Text Categorization is another classification task, where the goal is to assign one or more labels to a document (of variable length), indicating its topic or category. It can rely either on traditional NLP rules or on Machine Learning. This is a supervised process: you need a training set of documents with known labels to learn the connection between content and category. Once trained, the model can label new, unseen documents. One approach involves asking experts to write descriptions of each category. Then, by measuring the semantic similarity between a new document and these descriptions, the system can infer the most likely category. If multiple labels are allowed, you can also do multi-label text classification.
Text Categorization Use Cases
A classic case is spam detection. When you receive an email, your mail server analyzes the content, header, and other metadata to decide if the message is spam. If so, it's flagged and moved to a separate folder. This is done using a training set of labeled emails, annotated as spam or not spam. As spam tactics evolve, the model must be retrained regularly to stay effective. The prediction can rely on the header, subject line, sender, content, or even attachments. Another key use case is ticket management. Here, users send messages - emails or otherwise - about problems, questions, or requests. The goal is to automatically categorize these tickets based on their content and route them to the right person or team.
Machine Translation
Another interesting application of NLP is automated machine translation. In this task, you are given text in a source (original) language, and your goal is to translate it into a target language. The translation must convey with the rules of the target language, but at the same time it must preserve the meaning of the original message. So, the system needs to perform both understanding and generation - both stages are essential. The problem of automated translation is an open challenge, especially for low-resource languages, where training data is limited. There are three main approaches that have been used historically in machine translation.
- Rule- or dictionary-based
- Statistical methods
- Deep Learning
Rule-Based Machine Translation
The first approach to machine translation is the classical rule-based method. It is also known as Knowledge-based Machine Translation or Classical MT approach. It uses predefined rules, often crafted by experts, to map words or phrases from the source to the target language. The rule-based translation
Can’t find what you’re looking for?
Explore more topics in the Algor library or create your own materials with AI.
