Introducción a las bases de datos bioinformáticas y sus aplicaciones
Diapositivas de Johns Hopkins Medicine sobre Introducción a las Bases de Datos Bioinformáticas. El Pdf explora la bioinformática como disciplina que combina biología, informática y matemáticas para el análisis de datos biológicos, detallando las bases de datos secundarias para secuencias proteicas, funciones, mutaciones y enfermedades en el ámbito universitario de Informática.
Ver más68 páginas


Visualiza gratis el PDF completo
Regístrate para acceder al documento completo y transformarlo con la IA.
Vista previa
Introducción a las bases de datos Bioinformáticas
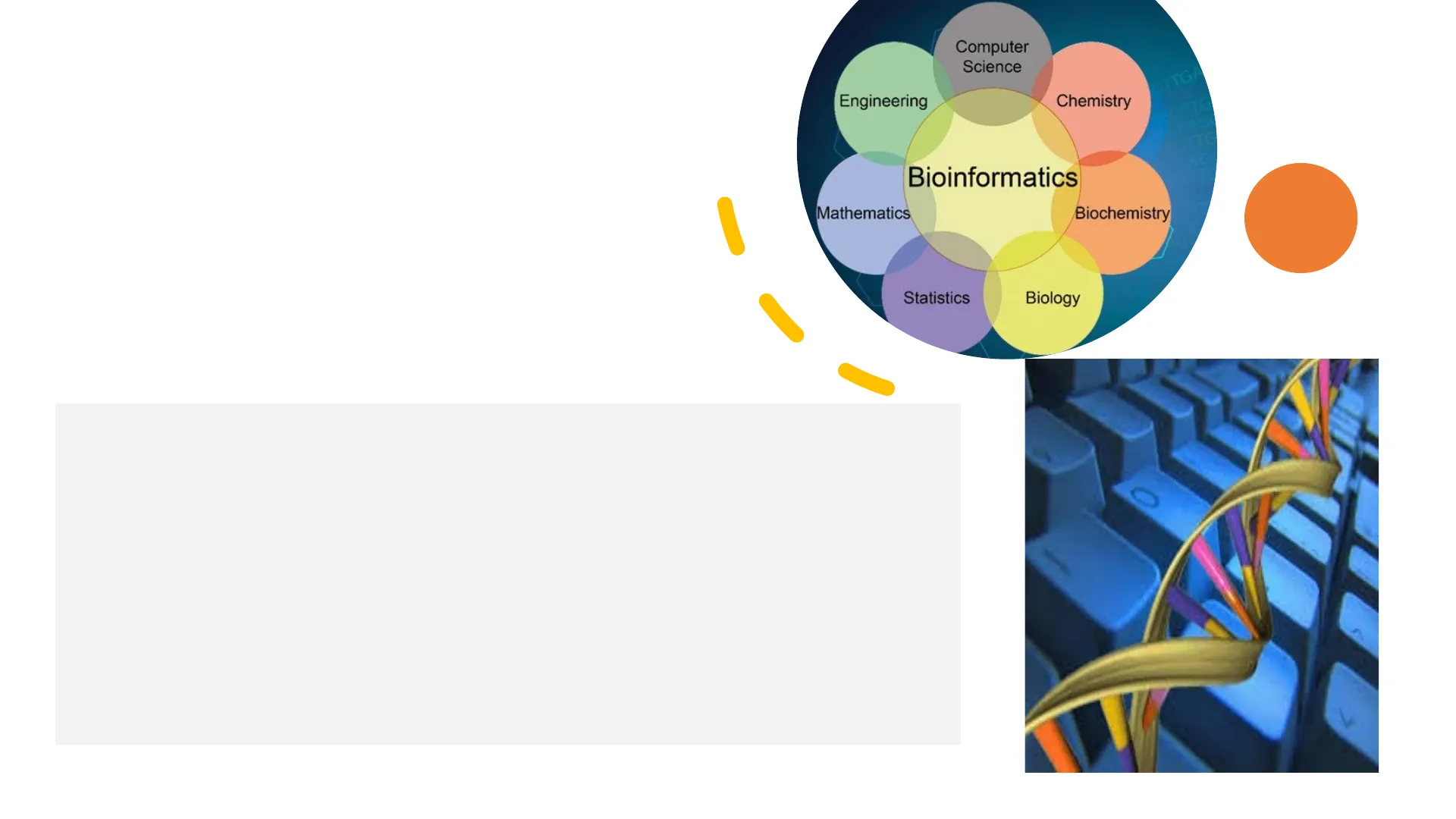
Definición de Bioinformática
La información biológica y la necesidad de la Bioinformática Bases de datos biológicas, bibliográficas y de patentesDefinición de Bioinformática La bioinformática es una disciplina científica que combina la biología, la informática y las matemáticas para analizar y procesar grandes volúmenes de datos biológicos. Se utiliza principalmente en el estudio de secuencias de ADN, ARN y proteínas, así como en la modelización de estructuras biomoleculares y la simulación de procesos biológicos.
Computer Science TG Engineering Chemistry Bioinformatics Mathematics Biochemistry Statistics Biology
Aplicaciones de la bioinformática
- Análisis de secuencias genéticas (genómica y transcriptómica).
- Predicción y modelado de proteínas (proteómica).
- Estudios evolutivos y filogeneticos. Desarrollo de fármacos y medicina personalizada.
- Estudio de microbiomas y metagenómica.
Es una herramienta fundamental en la biología moderna, especialmente en áreas como la biotecnología, la biomedicina y la investigación genética. Bioinformática-Ana Cámara-Artigas
Contexto histórico de la creación de la BIOINFORMATICA
Orígenes y avances científicos
proporcionados por la aplicación de los ordenadores al estudio de la BiologíaMargaret Oakley Dayhoff (1925-1983) Pionera en el campo de la bioinformática y realizó contribuciones fundamentales que han influido en el desarrollo de la disciplina. Sus principales avances incluyen:
- Primera Base de Datos de secuencias de proteínas. En la década de 1960, Dayhoff y su equipo recopilaron y organizaron secuencias de proteínas en un formato computacional. Publicó el Atlas de Secuencias y Estructuras de Proteínas (1965), considerado la primera base de datos de secuencias biomoleculares.
- Código de una letra para aminoácidos. Para simplificar la representación de secuencias de proteínas, creó el sistema de código de una sola letra para los 20 aminoácidos, que todavía se usa en bioinformática y biología molecular.
- Desarrollo de métodos para comparación de secuencias. Introdujo algoritmos para alineamiento de secuencias, facilitando la comparación y el análisis evolutivo de proteínas. Desarrolló la matriz de sustitución PAM (Point Accepted Mutation), utilizada para calcular la similitud evolutiva entre secuencias de proteínas.
- Pionera en el uso de computadoras en Biología Molecular. Una de las primeras científicas en aplicar el uso de computadoras para analizar datos biológicos. Sentó las bases para herramientas modernas como BLAST y otros programas de alineamiento de secuencias.
Su trabajo fue clave para el desarrollo de la bioinformática moderna y la genómica, influenciando desde la investigación de proteínas hasta la evolución molecular. Bioinformática-Ana Cámara-Artigas
Frederick Sanger (1918-2013)
Bioquímico británico conocido por sus contribuciones a la secuenciación de biomoléculas, lo que tuvo un impacto enorme en la bioinformática. Sus avances permitieron el desarrollo de herramientas computacionales para analizar secuencias biológicas, por lo que recibió el Premio Nobel de Química en 1958 y 1980.
- Método de secuenciación de proteínas (1950s). Fue el primero en determinar la secuencia completa de una proteína, la insulina, demostrando que las proteínas tienen una secuencia de aminoácidos específica. Este logro motivó el desarrollo de bases de datos y algoritmos para almacenar y analizar secuencias proteicas.
- Método de secuenciación de ADN (1977). Desarrolló el método de secuenciación de Sanger, que permitió leer secuencias de ADN de manera eficiente.Su técnica fue clave para la bioinformática, ya que generó grandes volúmenes de datos que requerían procesamiento computacional.
- Base de la Genómica y el Proyecto Genoma Humano (PGH). El método de Sanger se convirtió en la técnica estándar para la secuenciación de genes y genomas completos. Fue utilizado en el Proyecto Genoma Humano, lo que llevó al desarrollo de herramientas bioinformáticas como BLAST y bases de datos como GenBank.
Impacto en la Bioinformática: El trabajo de Sanger creó la necesidad de herramientas computacionales para analizar secuencias de ADN y proteínas, lo que impulsó la bioinformática como disciplina. Su legado sigue presente en la genómica moderna y en tecnologías de secuenciación más avanzadas. Bioinformática-Ana Cámara-Artigas
John Kendrew y Max Perutz
Realizaron contribuciones clave en la determinación de estructuras de proteínas mediante cristalografía de rayos X -> gran impacto en la bioinformática estructural y el modelado molecular.
- Determinación de la primera estructura de una proteína. Fueron las primeras estructuras de proteínas a nivel atómico: v Max Perutz resolvió la estructura de la hemoglobina en 1959. v John Kendrew determinó la estructura de la mioglobina en 1958.
- Impulso a la Bioinformática Estructural. Sus trabajos sentaron las bases para el desarrollo de la bioinformática estructural, que estudia la forma y función de las proteínas mediante modelado computacional. Proporcionaron datos cruciales para la creación de bases de datos como Protein Data Bank (PDB), donde se almacenan estructuras tridimensionales de proteínas.
- Uso de computación en la Biología Molecular. Perutz y Kendrew utilizaron computadoras primitivas para analizar los patrones de difracción de rayos X y modelar las estructuras proteicas. Esto llevó al desarrollo de algoritmos y software para modelado molecular, esenciales en la bioinformática moderna.
O. 02 HS Impacto en la Bioinformática: Gracias a su trabajo, hoy existen herramientas avanzadas para la predicción de estructuras proteicas, como AlphaFold y Rosetta, que son fundamentales en el diseño de fármacos y la biología computacional. Bioinformática-Ana Cámara-Artigas
Proyecto genoma humano
El Proyecto Genoma Humano (PGH) (1990-2003) fue un hito en la biología y la bioinformática que permitió la secuenciación completa del ADN humano. Su desarrollo impulsó la creación de nuevas herramientas computacionales y bases de datos para manejar grandes volúmenes de información genética. Su impacto sigue creciendo con avances en la genómica, medicina personalizada y biotecnología.
El genoma humano consta de ~ 3,200 millones (3.2 x 109) de pares de bases en el ADN. 46 cromosomas en total (23 pares): 22 pares de autosomas y 1 par de cromosomas sexuales (XX en mujeres, XY en hombres). Contiene alrededor de 25,000 genes codificantes. Solo ~1-2% del ADN codifica proteínas, el resto incluye regiones reguladoras, intrones y ADN no codificante que tiene funciones en la regulación génica, estructura del ADN y otros procesos biológicos. 99.9% del ADN es idéntico en todos los humanos, pero el 0.1% restante explica la diversidad genética y las diferencias individuales. Además del ADN nuclear, los humanos tienen un pequeño genoma en las mitocondrias (ADNmt), con 37 genes esenciales para la producción de energía.
El genoma humano es un mapa complejo que sigue siendo estudiado para comprender mejor la biología, las enfermedades y el envejecimiento.
nature the human genome Nuclear fusion Seafloor spreading Theviewtopmander Career prospects Science 15 February 2001 Vol 291 No. 5507 Pages 1145-1434 $9 THE HUMAN GENOME N AMERICAN ASSOCIATION FOR THE ADVANCEMENT OF SCIENCE Bioinformática-Ana Cámara-Artigas
Objetivos del PGH
- Creación y expansión de bases de datos genómicas. Se desarrollaron repositorios como GenBank, Ensembl y UCSC Genome Browser, esenciales para almacenar, analizar y compartir datos genómicos. Estos recursos permiten a científicos de todo el mundo acceder y estudiar secuencias de genes en organismos diversos.
- Desarrollo de algoritmos para el análisis de ADN. Se mejoraron herramientas como BLAST y FASTA para la comparación y alineamiento de secuencias genéticas. Se crearon algoritmos avanzados para predecir genes, detectar mutaciones y analizar la evolución del ADN.
- Avance en la medicina personalizada y farmacogenómica. La información del genoma humano ha permitido diseñar terapias personalizadas basadas en la genética de cada individuo. Se han desarrollado algoritmos para identificar variantes genéticas asociadas a enfermedades y predecir respuestas a fármacos.
- Aceleración de la Biología Computacional. Se creó la necesidad de supercomputadoras y plataformas de big data para analizar grandes cantidades de información genética. Esto llevó a la evolución de inteligencia artificial y aprendizaje automático en el análisis genómico.
- Impulso a la secuenciación de nueva generación (NGS). Gracias al PGH, se desarrollaron métodos de secuenciación masiva (NGS), reduciendo costos y tiempos de análisis del ADN. Esto ha permitido proyectos como 1000 Genomas y estudios de genómica en enfermedades complejas como el cáncer.
Bioinformática-Ana Cámara-Artigas
Impacto actual de la Bioinformática
La bioinformática tiene un gran impacto en muchas áreas de la biotecnología y las ciencias biomédicas Se estudiarán a lo largo del curso. Algunos ejemplos son ...
Situación actual de la Bioinformática
ALSO TOOLS DISK TARGET CONNECTOMICS ORGANIZATIONS APPLIED SENSOR MAY SHARED DEFINITION MOVING LARGER CONTINUES SOCIAL WITHIN ZETIABYTES PRACTITIONERS CAPTURE THOUGHT BUSINESS & INTERNET ISTRIBUTED GENOMICS DESCRIBING RADIO-FREQUENCY SETS COMPLEXITY MANAGEMENT TERABYTES NOW BIOLOGICAL PROCESSING UBIQUITOUS PETABYTES INCLUDE CAPACITY BIRED WORLD'S NETWORKS DATABASES SIZE MPPE SEARCH DIFFICULTY
La bioinformática genera enormes cantidades de datos a través de tecnologías como:
- Secuenciación de ADN y ARN (NGS - Next-Generation Sequencing).
- Proteómica y metabolómica (estudio de proteínas y metabolitos).
- Imágenes biomédicas y estructurales (rayos X, resonancia magnética, etc.).
- Interacciones biomoleculares (redes de genes y proteínas).
El Big Data en bioinformática permite gestionar, analizar e interpretar estos datos de manera eficiente mediante técnicas de inteligencia artificial, aprendizaje automático y computación en la nube.
Tecnologías clave en bioinformática y Big Data
Computación en la nube: Amazon Web Services (AWS), Google Cloud ... Bases de datos masivas: GenBank, Ensembl, PDB .... Algoritmos de machine learning: Redes neuronales, árboles de decisión, clustering. Lenguajes de programación: Python, R, Java, SQL para análisis de datos biomédicos. SYSTEMS TOLERABLE DATASTAGE PARALLEL GROW MASSIVELY ABILITY HUNDREDS RECORDS TENS COMPLEX ANALYLES BIG SET EXAMPLES
¿Non has encontrado lo que buscabas?
Explora otros temas en la Algor library o crea directamente tus materiales con la IA.
