Análisis de datos en tablas de contingencia, apuntes de Universidad
Documento de Universidad sobre Análisis de datos en tablas de contingencia. El Pdf aborda el estudio de la relación entre variables categóricas, con ejemplos detallados y fragmentos de código R para la ejecución de tests estadísticos en Matemáticas.
Ver más13 páginas


Visualiza gratis el PDF completo
Regístrate para acceder al documento completo y transformarlo con la IA.
Vista previa
Análisis de Datos en Tablas de Contingencia
Es importante, porque se verá la diferencia entre tipos de datos v/s todos los otros modelos (Donde todos los datos eran de variables continuas).
Tabla de Contingencia: Pruebas y Características
¿Qué pruebas podemos realizar? - > Test de independencia y test de homogeneidad Va a ser una tabla de doble entrada, en donde tenemos una característica que va a definir las filas y una característica que va a definir las columnas. Se cruzan o cotejan 2 características. Para ello se toman "n" muestras. Cada una de estas "n" muestras se va a clasificar según lo observado por filas y por columnas.
F11, F1J, etc -> son frecuencias, no es el resultado de una variable continua, si no un dato de FRECUENCIAS, es decir, cuántas observaciones se han recabado para combinación de fila y columna.
Ejemplo de Prueba Sensorial
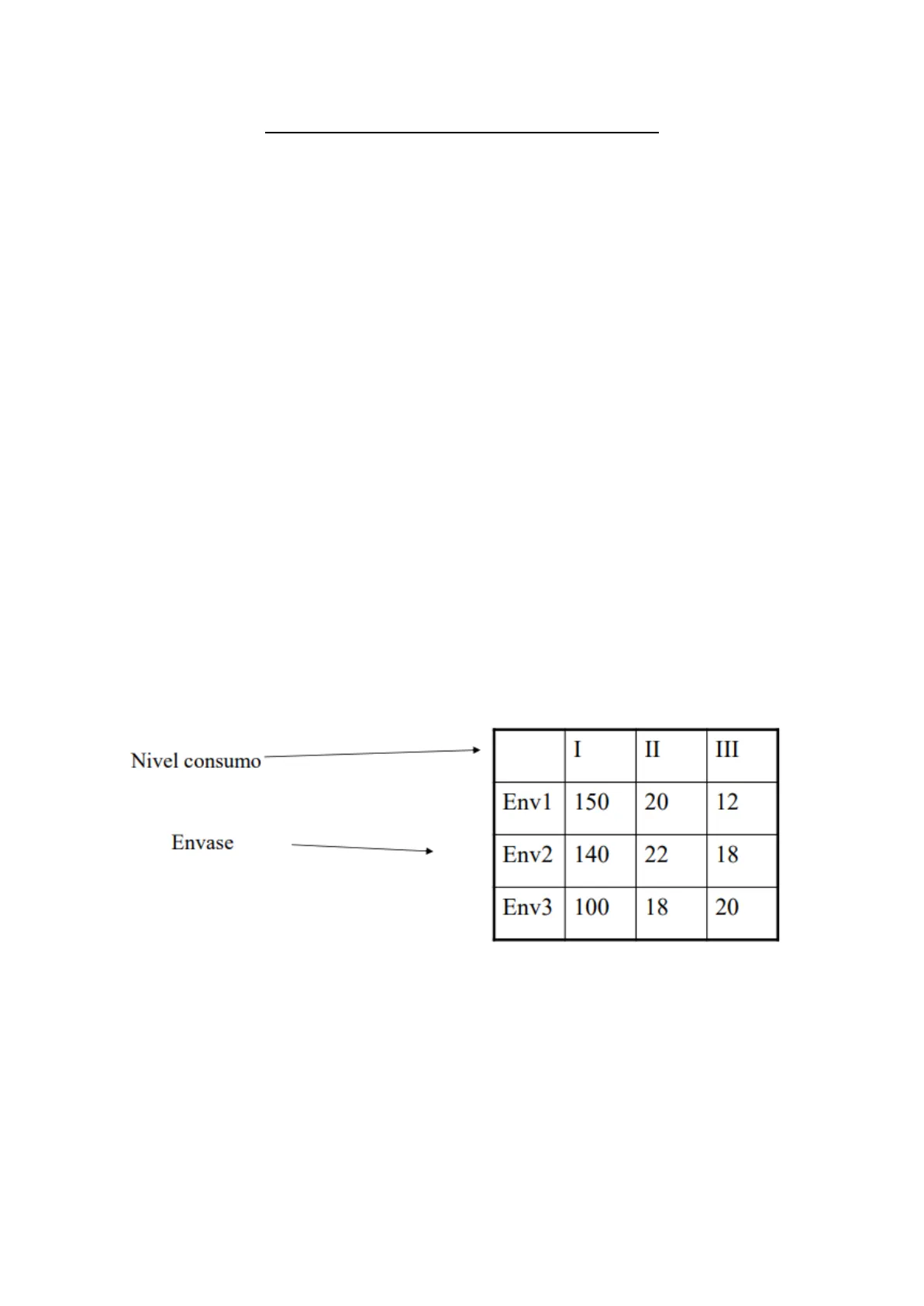
Ejemplo: en una prueba sensorial se toma una muestra de 500 consumidores de un producto. El producto se presenta según 3 modelos de envase distinto (Envase 1 [por ejemplo, vidrio], Envase 2 [p.ej, lata], Envase 3 [p.ej, familiar]). Por otro lado, al consumidor se le pide que indique su frecuencia de consumo (I: Elevado [5 o más a la semana]; II: Normal [entre 2 y 4], III Esporádico [1 o ninguno]). -> Se trata de estudiar la relación entre la frecuencia de consumo y la elección del envase.
Nivel consumo I II III Env1 150 20 12 Envase Env2 140 22 18 Env3 100 18 20
Env1 x I -> 150 consumidores se han autoclasificado envase tipo I (vidrio) y frecuencia de consumo tipo I (elevada) ESTOS SON DATOS DE FRECUENCIAS, NO SON MEDIDAS CONTINUAS. Por eso, a este tema también se le llama ANÁLISIS DE DATOS DE FRECUENCIAS.
Tipos de Análisis en Tablas de Contingencia
En las tablas de contingencia vemos 2 tipos de análisis:
- Test de homogeneidad.
- Test de independencia.Hay bastante diferencia entre ambas situaciones. A veces ocurre que, según miremos el enunciado, no es muy claro.
Estudio Hormonal y Característica Genética
1 .- En cierto estudio se realiza una medida hormonal que se clasifica en 2 categorías (A normal y B alta) después de la ingesta de cierto producto alimenticio. Se trata de estudiar si cierta característica genètica (P presente A ausente) condiciona el resultado. Para ello se han utilizado 50 voluntarios con presencia de la característica y 50 voluntarios sin la característica. Los resultados obtenidos son:
A B P 32 18 A 26 24 ¿Se puede aceptar que la distribución del resultado es la misma en ambos grupos? Analizar los resultados del experimento.
n = 50 ->P; n = 50 -> A
A (normal) B (alta) P (característica genética presente) 32 18 50 A (característica genética ausente) 26 24 50
No se está tomando un individuo al azar y ver si presenta la característica genética o no. Se controla esa parte, ya hay 50 y 50. Queremos ver si hay diferencias respecto a la característica genética, que es lo que estamos controlando. Lo que quiero ver, es que, si respecto a la característica genética, van a haber diferencias en la medida hormonal. Estamos comparando las probabilidades de que sea alta o normal la medida hormonal en función de la característica genética. Ver si tener o no tener la característica genética afecta la prueba de medida hormonal.
Homogeneidad: Prueba de Comparación
Cuando la idea sea esta -> HOMOGENEIDAD -> PRUEBA DE COMPARACIÓN O COMPARATIVO -> ahí radica la forma de ver y entender el diseño.
En este caso:
- HO = homogeneidad -> la probabilidad de que ocurra A condicionado o sabiendo que la característica genética está presente ES LA MISMA PROBABILIDAD de que A ocurra con la característica genética. En pocas palabras, existe poca relación.
- P(A/presente) = P(A/ausente)
- P(B/presente) = P(B/ausente) COMPARAR LAS PROBABILIDADES DE QUE OCURRA EL SUCESO "A" SI LA CARACTERÍSTICA GENÉTICA ESTÁ PRESENTE O AUSENTE. Tienes controlada la muestra de entrada. Acá no hay que calcular nada más, simplemente se resuelve el test y ya está.
- H1 = heterogeneidad
Script y Resultados del Test Chi-Cuadrado
#SCRIPT ejercicio 1 tabla=rbind(c(32,18),c(26,24)) colnames(tabla) <- c("A","B") rownames(tabla) <- c("P","A") tabla Xsq <- chisq.test(tabla)Xsq A B P 32 18 A 26 24 Pearson's Chi-squared test with Yates' continuity correction data: tabla X-squared = 1.0263, df = 1, p-value = 0.311 p valor > 0,05 -> se acepta H0 No rechazamos que la probabilidad es la misma en función de que se tenga o no se tenga la característica genética.
Estudio de Dieta y Colesterol
Otro ejemplo: 3 .- Se realiza un seguimiento de 900 voluntarios durante 2 años a los que se les ha realizado un estudio previo de salud comprobando un estado normal en las analíticas. Una vez finalizados los dos años se clasifican según una tabla en función de que su dieta haya sido alta en cierto tipo de grasas y también en función de que presenten o no un nivel alto de colesterol ( mayor o menor de 200). Los resultados obtenidos son:
Nivel Normal Col Nivel Alto Col Grasas Normal 480 78 Grasas Altas 252 90 Analizar los resultados estadísticos del estudio.
n = 900
Nivel normal de colesterol Nivel alto de colesterol Grasa normal 480 78 Grasa alta 252 90
Si quiero relacionar el que el colesterol sea alto o normal con respecto a una dieta normal en grasas o alta en grasas. Esto es un muestreo RETROSPECTIVO, porque aunque tengas los voluntarios a priori, al final hasta que no ha pasado el tiempo todavía no puedes acceder a los resultados o controles previos.
Prueba de Independencia: Dieta y Colesterol
Acá estoy relacionando niveles de colesterol con dieta. Esto es una PRUEBA DE INDEPENDENCIA.
Acá las hipótesis:
- HO: independencia -> no hay relación entre dieta y niveles de colesterol (o entre filas y columnas)
- H1: dependencia Este test, una vez resuelto, si se acepta H0, ahí se acaba, no se siguen haciendo análisis. Pero si se acepta H1 (o se detecta dependencia), esto no es suficiente como conclusión. Ahora HAY QUE MEDIR LA RELACIÓN DE DEPENDENCIA.
-> Si estás con datos que has controlado, y lo quieres tomar como un test de independencia, no se puede hacer, porque en este tipo de test, el muestreo no puede estar controlado por filas o columnas, se cometería un error estadístico. -> Si tenemos una tabla de contingencia, siempre subyace la idea de la relación. Por tanto, la diferencia es sutil al momento de distinguir.
Encuesta de Producto y Etiquetado
Otro ejemplo: 4 .- En el diseño de un producto se realiza una encuesta en la que participan 900 potenciales consumidores. Siendo el mismo producto, se presenta bajo 3 tipos de etiqueta y envase. El potencial consumidor realiza la degustación y clasifica en producto en tres categorías ( A normal, B bueno, C muy bueno).
Los datos obtenidos son: (a partir de 300 consumidores por etiquetaje)
A B C Etiquet 1 128 150 22 Etiquet 2 140 130 30 Etiquet 3 110 120 70 Analizar los resultados estadísticos del experimento.
Este ejemplo, también es de homogeneidad. Estoy comparando la degustación en base a etiquetas. Yo no le digo al consumidor lo que hay dentro. Intento ver si hay desviaciones en función de la etiqueta. En este caso, no tendría mucho sentido una prueba de independencia, porque no hay mucho que relacionar. Estoy literalmente comparando etiquetas. Idealmente que sea balanceado, porque sino, en las estimaciones, no van a entrar en la región crítica. Técnicamente no es necesario que lo sea, pero desde el punto de vista de las probabilidades estadísticas y de ciertos intervalos de confianza que van a interferir en la región crítica, es preferible que lo sea.
Como son datos de FRECUENCIA, se diferencia de los modelos ANOVA. Acá la marca es algo así como un factor, pero los datos no son continuos, por lo que no se puede analizar con un modelo ANOVA.
Cálculo del Test de Ji Cuadrado
Si el test es de homogeneidad o de independencia, el análisis estadístico y por tanto la región crítica, se calcula DE LA MISMA FORMA, es decir, con el test de JI CUADRADO.
Tabla de la ji cuadrado Funciona comparando las frecuencias observadas y las frecuencias téoricas.
- Se calcula el estadístico de test: x2 = X2 = EL i=1 j=1 I (fü-nim"mj In)} nim1mj /n
- Se comparan frecuencias observadas y frecuencias teóricas
- Se compara con el valor de tablas de la distribución ji-cuadrado (I-1)(J-1) g.l.
- En caso de test de aceptar dependencia en el test de independencia, se debe medir la dependencia mediante el coeficiente de contingencia.
Ejemplo de Consumo de Yogurt y Natillas
Yogurt Sí No Natillas Sí 180 -> F1.1 70 -> F 1.2 Suma de fila 1: 250 = n1m No 210-> F2.1 40 → F2.2 Sua de fila 2: 250 = n2m Suma de columna 1: 390 = nm1 Suma de columna 2: 110 = nm2
Queremos ver si hay relación entre consumo de yogurt y consumo de natillas. n = 500 personas
Esto es un test de independencia:
- HO: independencia -> no hay relación entre el consumo de una cosa con la otra
- H1: dependencia
Frecuencias Observadas y Teóricas
Frecuencia teórica: de los 500 individuos, cuál sería la frecuencia que teóricamente, si hubiera independencia, debería encontrar para cada una de estas casillas.
Esto da pie a las frecuencias observadas y las frecuencias teóricas:
Frecuencias observadas Frecuencias teóricas 180 250 * 390 / 500 = 195 70 250 * 110 /500=55 210 250 * 390 / 500=195 40 250 * 110 /500=55
Por ejemplo, la teórica para el dato "180" es -> La suma de la fila + la suma de la columna / número total de datos -> 250 * 390 / 500 Si observadas y teóricas se parecen mucho, la ji cuadrada es baja, el valor estadístico del test sería bajo y tendremos que aceptar la hipótesis nula. En caso contrario, se acepta la h1.
En este caso, se parecen bastante, aparentemente tiene una tendencia a que se acepte la H0.
Cálculo de la Ji Cuadrada Experimental y p-valor
Si ahora, calculamos la JI CUADRADA EXPERIMENTAL = [((180-195)^2]/195 + [((70-55)^2)/55] + [((210-195)^2)/195] + [((50-55)^2)/55] -> 6,85 // 10,48
Ahora esto se compara con valores de tablas -> los grados de libertad son "el número de filas -1"; y-1->2j->2 y-1*j-1 = 1
Ahora, obtendremos la cola para 10,48 -> buscar el p valor. Con R, el p valor, en este caso, será: 1-pchisq p es función de distribución. pchisq = área a la izquierda 1-pchisq = área a la derecha Con R, nos dio = > 1-pchisq (10. 48, 1) [1] 0.001206738 Como es menor a 0,05, se acepta la H1 -> aunque nos parecía que se aceptaba bastante, no era suficiente como para no rechazar la hipótesis nula. Aceptamos que hay dependencia de lo que ocurre. Ahora veremos si esta dependencia si es fuerte o débil, y mediremos la dependencia.
https://www.disfrutalasmatematicas.com/datos/calculadora-chi-cuadrado.html
Medición de la Dependencia: Coeficientes
Para medir la dependencia, tenemos el COEFICIENTE DE CONTINGENCIA DE PEARSON: C = raíz cuadrada de la ji cuadrado experimental / n + ji cuadrada experimental C = raíz cuadrada de 10,48 / 500 + 10,48 Cuanto más se acerca a 0, hay más dependencia, y viceversa. Pero hay una cota máxima para este valor.
Ahora debemos dividir la C / raíz cuadrada de 2-1/2 -> coeficiente de contingencia de PAWLIK. = 0,14 / raíz cuadrada de 1/2 = 0,19 -> medida entre 0 y 1 que intenta medir la dependencia -> el coeficiente de contingencia de PAWLIK nos da un valor reducido o bajo, por lo tanto, a pesar de haber detectado dependencia, concluimos que se trata de una dependencia reducida -> la relación entre consumo de yogurt y natilla es baja.
TODO ESTO SÓLO SE VA A REALIZAR EN CASO DE TEST DE INDEPENDENCIA, NO DE HOMOGENEIDAD.
Si tienes 3 filas y 4 columnas, siempre pones el mínimo entre filas y columnas.
Repaso del Parcial: Ejercicios
Sesión 25-11-2024: repaso del parcial del 22 de noviembre Modelo B de la prueba, parte de ejercicios:
- Mejora de producción de cierta harina, se analiza el efecto de 2 composiciones de un aditivo A (Ad_1 y Ad_2) y del efecto que tiene sobre la producción de la utilización del cereal.
¿Non has encontrado lo que buscabas?
Explora otros temas en la Algor library o crea directamente tus materiales con la IA.
