Méthodologie de la recherche et statistique pour l'université
Document de l'Université sur la méthodologie de la recherche et la statistique. Le Pdf explore la présentation et le résumé des données, la symétrie et l'asymétrie des distributions, ainsi que les types d'études, pour les mathématiques au niveau universitaire.
See more18 Pages


Unlock the full PDF for free
Sign up to get full access to the document and start transforming it with AI.
Preview
Présenter et résumer les données
Symétrie des observations
La symétrie ou l'asymétrie des observations d'une variable donnée a une grande importance dans l'évaluation ultérieure des tests statistiques qui seront appropié.
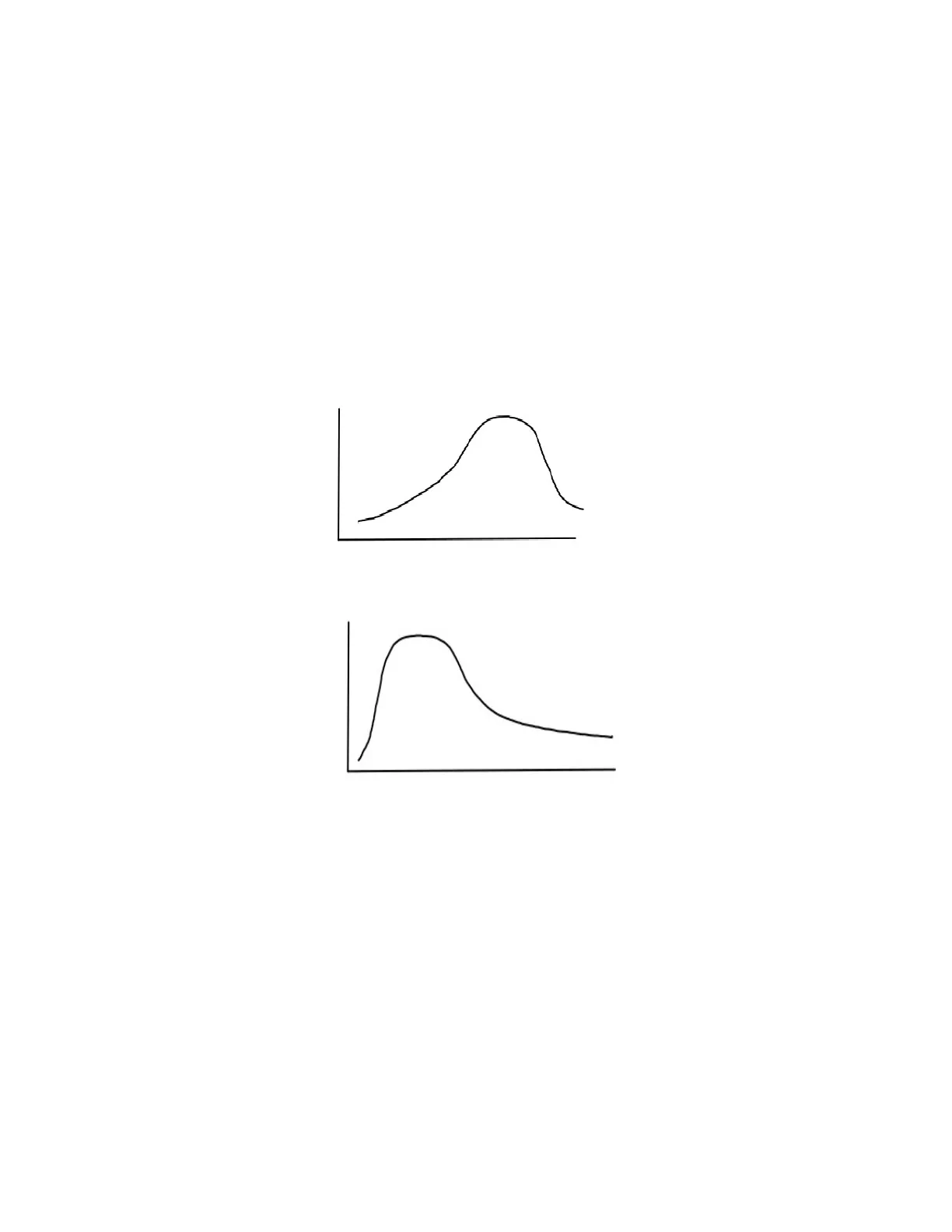
Si les observations d'une variable se produisent seulement dans une direction donnée, par exemple, quelques valeurs basses ou bien des valeurs élevées, la distribution sera une distribution asymétrique.
Si les valeurs plus insolites sont à gauche (comme dans l'image ci-dessous), la distribution est dite asymétrique négative ( la moyenne et la médiane sont à la droite la mode).
Si les valeurs plus insolites sont à droite (comme dans l'image ci-dessous), la distribution est dite asymétrique positive ( la moyenne et la médiane sont à la gauche la mode)
Conseils utiles sur la symétrie
- la moyenne et la médiane sont les mêmes, la distribution est symétrique
- Si la moyenne est supérieure à la médiane, la distribution est asymétrique positif*
- Si la moyenne est inférieure à la médiane, la distribution est asymétrique négatif*
(* N'arrive pas toujours! Voir par exemple: http://www.amstat.org/publications/jse/v13n2/vonhippel.html http://www.amstat.org/publications/jse/v19n2/doane.pdf )
Exemples de distribution
a) 5, 10, 14, 15, 16, 20, 25 la distribution est symétrique, la moyenne et la médiane sont les mêmes (15) b) 5, 10, 10, 15, 15, 15, 20, 20, 40 la distribution est asymétrique positive, la moyenne est supérieur à la médiane
c) -30, 10, 10, 15, 15, 15, 20, 20, 25 la distribution est asymétrique négative, la moyenne est inférieure à la médiane
- la moyenne est utilisée pour les distributions symétriques et de données numériques
- la médiane est utilisée pour les données ordinales ou numérique si la distribution est asymétrique
Il ya certaines mesures mathématiques habituels qui sont susceptibles d'être utiles et visent à traduire le degré de symétrie d'une distribution (les paragraphes précédents) ou comment ses valeurs sont distribués, par exemple si vous avez un pic, ou si d'autre part il est plus "aplatie". Leurs mathématiques de similitude avec les quantités que nous avons examinés dans la dernière classe (moyenne, variance) justifie leur introduction à ce stade.
La variance implique la somme des écarts au carré Σ (x-x)2 (n-1) s'= et pour cette raison est parfois appelée la deuxième moment central m2.
Peut être défini moments centrés d'ordre supérieur, à savoir, E(x-x)3 n E (x-x) 4 E (x-x) 2 n .Il est possible de travailler avec ces nouveaux montants afin m3= e m4= d'éliminer rapidement les autres propriétés sur la façon dont les données sont distribuées.
- La asymétrie/skewness de la distribution peut être calculée en divisant le troisième moment par l'écart-type au cube. skew=s3= n.s E(x-x)3 ** 3 Une skew de zéro signifie que la distribution est symétrique. Une valeur positive de s3 signifie que la distribution est asymétrique positive et un valeur négatif qui est asymétrique négative.
Exemple de calcul du skewness
Calculez le skewness de les données suivantes en utilisant le SPSS a) 5, 10, 10, 15, 15, 15, 20, 20, 40 (skew=1.7) b) -30, 10, 10, 15, 15, 15, 20, 20, 25 (skew =- 2.5).
Dans SPSS choix, Analyze -> Descriptive Statistics -> Frequencies option Statistics choix Skewness
- le coefficient d'aplatissement/Kurtosis ("niveau d'aplatissement") peuvent être évaluée en divisant le quatrième moment par l'écart-type elevée à quatre. kurtosis = s4= Σ(x-x)4 n.s 4
La distribution normale (que faire d'une vaste consultation ultérieure) à une coefficient d'aplatissement de 3, et par conséquent, si une distribution a distribué plus de valeurs que la distribution normale le coefficient d'aplatissement est inférieur à 3, sinon il sera plus de 3. Habituellement, le montant est calculé soustraits de 3 dans le logiciel d'analyse statistique. Dans ce cas, si la valeur de l'aplatissement est égale à zéro la distribution est mesokurtic. Si elle est supérieure à zéro, leptokurtique et inférieure à 0, platicurtique.
( ** Par souci de simplicité, les formules prévues notamment pour les troisième et quatrième moments sont valides uniquement pour les très grands échantillons, qui sont de bonnes estimations des valeurs réelles dans la population. Les formules utilisées par les packages statistiques tels que SPSS sont plus complexe-voir exercices de cours pratiques).
- Dans la distribution platicurtique
- PIC est plus arrondi avec des queues plus courte et plus légère
- par rapport à la distribution normale, il est une plus faible probabilité d'avoir des valeurs près de la moyenne, ainsi que d'avoir des valeurs extrêmes.
- Dans la distribution leptokurtique
- PIC est plus aiguë avec des queues plus longues et plus lourdes
- par rapport à la distribution normale, il est une plus grande probabilité d'avoir des valeurs près de la moyenne, ainsi que d'avoir des valeurs extrêmes.
Dans l'image suivante les couleurs ci-dessous le noir représentent les distributions platicurtiques et ci- dessus leptokurtiques.
0.8 D, 3 S, 2 L, 1.2 0.7 N, 0 C, -0.59376 W, -1 U, -1.2 0.6 0.5 0.4 0.3 0.2 0.1 0 - 5 - 4 - 3 -2 - 1 0 1 2 3 4 5
Référence: http://upload.wikimedia.org/wikipedia/commons/e/e6/Standard_symmetric_pdfs.png
Remarque: les valeurs du coefficient d'asymétrie ou aplatissement doivent être évaluées en ce qui concerne la signification statistique afin de tirer des conclusions valides. Les tests statistiques sont soumises à être abordées plus tard.
Exemples de coefficient d'aplatissement
Calculer le coefficient d'aplatissement des données suivantes en utilisant le SPSS a) 5, 10, 10, 15, 15, 15, 20, 20, 20, 20, 25, 25, 25, 30, 30, 35 (-0.46, i.e., valeurs plus dispersés que dans une distribution normale, distribution d'échantillonnage plus "aplatie") b) 5, 10, 10, 10, 15, 15, 15, 20, 20, 20, 25, 25, 25, 30, 30, 30, 35 (distribution plus plate que le précédent, le coefficient d'aplatissement est plus négatif, -0.99)
Types d'études
Classification des modèles d'étude
- Les études d'observation
- Descriptifs/études de groupes de patients ou de series de cas
- Étude de cas-témoins (rétrospective, longitudinale) - propriétés: causes et l'incidence de la maladie, l'identification des facteurs de risque
- Étude transversale, par sondages, épidémiologiques (prévalence). Propriétés: description de la maladie, diagnostic et mise en scène, les processus et les mécanismes de la maladie
- Études de cohorte (prospetcives, longitudinale) - Propriétés: causes et l'incidence de la maladie, histoire naturelle, pronostic, l'identification des facteurs de risque
- Études de cohorte historique (pas abordé)
- Études experimentales
- Essais avec contrôles parallèles aléatoires
- Essais avec contrôles parallèles non aléatoires
- Essais avec contrôles séquentielles: auto contrôles
- Essais avec contrôles séquentielles: croisés
- Études de méta-analyse ("meta-analysis")
La classification d'une étude des types ci-dessus n'est pas toujours immédiat et facile à faire. Toutefois, cette classification est importante car, en plus de guider l'enquêteur dans la phase de conception d'une étude de recherche et de comprendre ce qu'il faut faire et les précautions respectives, seront également aider à determiner le type d'analyse statistique à faire.
Études D'Observation
Descriptif/ études de groupes de patients ou de séries de cas
Les études descriptifs / groupes de patients ou de séries de cas pas impliquent généralement des groupes de contrôle, à savoir les individus qui ont pas la maladie ou condition à laquelle effectuer une comparaison. Non pas généralement une hypothèse de recherche à tester et ne sont pas prévues études. Sont destinés à décrire les caractéristiques intéressantes observées dans certains groupes de patients, dans de courtes périodes de temps.
Ces études sont rapides à réaliser et peuvent être utiles pour obtenir les directions pour servir de point de départ à une étude plus approfondie. Cependant, ils sont sensibles à de nombreux biais dans la sélection de l'échantillon ou les caractéristiques observées.
Exemple d'étude descriptive
. Morbidity and Mortality Weekly Report, Centers for Disease Control and Prevention, "Pneumocystis pneumonia - Los Angeles", 5 Junho 1981 (a "descoberta" do HIV). Référence: http://www.cdc.gov/mmwr/preview/mmwrhtml/june_5.htm, Gottlieb et al
Étude cas-témoins (cas-contrôles)
Une étude de contrôle de cas ou cas-témoins, vise répondre à la question "Qu'est-il arrivé?".
Dans ce type d'étude les cas sont comparées à des contrôles de manière rétrospective. Les cas sont des personnes sélectionnées en fonction d'une maladie ou d'un résultat particulier, les contrôles sont des personnes sans la maladie ou le résultat. Le passé de cas et les témoins (contrôles) est analysée au détail dans une tentative d'identifier la présence de caractéristiques dans les cas qui ont influencé l'apparition de la maladie ou de résultat qui ne sont pas présents de manière importante dans l' historique du contrôles. Dans le cas des maladies infectieuses sera cherché à déterminer si les cas ont été exposés à un agent infectieux que les contrôles n'étaient pas.
Les enquêteurs utilisant d'habitude d'appariement dans ce type d'études, pour associer des contrôles avec les cas afin qu'ils aient la même âge, le sexe, l'origine ethnique, etc., En particulier quand ont considére qui peuvent confondre les résultats.
Facteurs de risque/ exposition Cas-contrôle + Cas + - - Contrôles > temps Début de l'étude Direction de la question: "Ce qui s'est passé ?"
Références: Sur la base de la figure 2-1, BCB4. Le bleu indique des sujets exposés. Le signe + indique les sujets positifs / maladie / etc.
Exemple d'étude cas-témoins
Prenons un exemple hypothétique dans laquelle il explore les facteurs de risque de développer un cancer de la tête et du cou. Nous sommes allés par quatre phases:
1) Seléction des cas 200 patients arrivent à l'hôpital et sont diagnostiqués avec cancer de la tête et du cou avec critères cliniques bien dèfini (alors que l'étude peut être reproduit par d'autres investigateurs)
2) Seléction des contrôles 200 patients en jumelant avec des pairs du même sexe et de l'âge,à partir de la même région de patients.
3) La mesure du facteur de risque Supposons que les facteurs de risque à analysé sont: - nombre moyen de cigarettes fumées par jour pendant les 10 dernières années - la concentration de mercure dans le corpe - la consommation de boissons gazeuses et des concentrations élevées de sucre - présence d'un virus spécifique peut être faites interviews et des enquêtes, analyse des registres hospitaliers, l'analyse des registres cliniques, etc. pour évaluer ces facteurs de risque. Le manque de standardisation de cette information, déffaillances de la mémoire d'intervenants, etc. peut limiter le succès des études cas-témoins
4) L'analyse de l'association Si un facteur de risque important est par exemple le vírus, et cela est associée au développement du cancer de la tête et du cou, puis nous aurons une plus grande fraction de personnes dans les cas avec exposition au vírus que dans les contrôles. Si, d'autre part, le facteur de risque n'est pas du tout lié au développement de ce cancer, la fraction de personnes exposées au vírus sera similaire dans les deux groupes.
Pas de mesures mathématiques seront adressées à quantifier mathématiquement le risque en cas des l'études cas-témoins.
Exemple de la littérature
"Obesity and the risk of myocardial infarction in 27,000 participants from 52 countries: a case-control study" Yusuf S, Hawken S, Ounpuu S, et al. (November 2005), Lancet 366 (9497): 1640-9. doi:10.1016/S0140-6736(05)67663-5. PMID 16271645. En comparant l'indice de masse corporelle à raison "waist-to-hip" en termes d'association avecl'infarctus du myocarde?
Can’t find what you’re looking for?
Explore more topics in the Algor library or create your own materials with AI.
