Statistica per big data economico/aziendali: Analisi delle Componenti Principali
Slide dall'Università degli Studi di Milano su Statistica per big data economico/aziendali: Analisi delle Componenti Principali (ACP). Il Pdf illustra i modelli supervisionati e non supervisionati, i passaggi per l'applicazione dell'ACP e i criteri di selezione delle componenti, con un esempio di screeplot, per la materia Economia a livello universitario.
Mostra di più40 pagine


Visualizza gratis il Pdf completo
Registrati per accedere all’intero documento e trasformarlo con l’AI.
Anteprima
Statistica per big data economico/aziendali
Analisi delle Componenti Principali (ACP)
Andrea Cappozzo
andrea. cappozzo@unimi.it
@AndreaCappozzo
andreacappozzo. rbind.io
STUDIORU
M
IF
TAS
DIC
INO
ANENSIS
UNIVERSITÀ
DEGLI STUDI
DI MILANO
Anno accademico 2023/2024
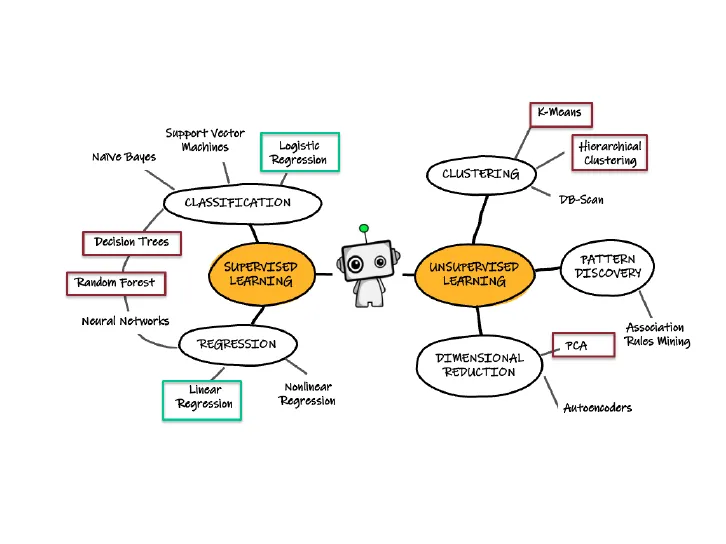
Modelli supervisionati e non supervisionati
metodi
K-Means
Support Vector
Machines
Naive Bayes
Logistic
Regression
Hierarchical
Clustering
CLUSTERING
CLASSIFICATION
DB-Scan
Decision Trees
SUPERVISED
LEARNING
UNSUPERVISED
LEARNING
PATTERN
DISCOVERY
Random Forest
Neural Networks
Association
Rules Mining
PCA
DIMENSIONAL
REDUCTION
Linear
Regression
Nonlinear
Regression
1
REGRESSION
Autoencoders
1/39
Unsupervised learning: riduzione dimensionale
Spazio complesso e di alta dimensione dove vivono i dati
Spazio Euclideo a dimensioni ridotte
.
.
.
.
-7
L
-
2/39
Analisi in componenti principali (ACP)
- Data una matrice di dati X di dimensione n x p con n
osservazioni e p variabili, si vuole ridurre la dimensionalità
dei nostri dati (sulle colonne p) ottenendo un numero q < p
di variabili, con la minima perdita possibile di informazioni.
" In questo caso, con "informazioni" si intende "variabilità" e,
in particolare, "varianza" dei dati originali.
- Questa riduzione dimensionale viene eseguita ai fini di una
migliore interpretabilità dei dati o, ai fini delle tecniche di
regressione, di avere predittori "compressi" (o, se vogliamo,
"artificiali") dai predittori originali. - Dal punto di vista geometrico dobbiamo trovare una
proiezione della matrice di dati X di dimensioni n x p a una
nuova matrice di dati Z avente dimensioni n x q, in modo
che i nuovi dati in questa matrice rappresenteranno in
maniera il più possibile fedele i dati originali nella matrice
X.
3/39
ACP: esempio
- Supponiamo di voler quantificare una "prestazione atletica"
di un gruppo di n giovani. - Consideriamo p = 5 competizioni sportive: salto in alto,
100m, salto in lungo, 1500m, farfalla 100m (nuoto)). - Partendo da questi dati vogliamo costruire una variabile di
punteggio artificiale z contenente quante più informazioni
possibili sulle 5 competizioni. - Questa nuova variabile dovrebbe essere una combinazione
lineare delle variabili originali e avere la varianza massima,
cioè per l'atleta i:
Zil = @11x11 + @21x12 + ... + aplxip,
in cui il secondo indice in zi1 indica che ci riferiamo alla
prima nuova variabile, detta componente. - In termini matriciali abbiamo: z1 = Xa1.
4/39
Varianza della prima componente: desiderata
" La combinazione lineare sara' z1 = Xa1.
- Quale sara' il valore di Var(z1)?
- Sara' uguale a a-Sa1, dove S è la matrice di
varianza-covarianza della matrice X. - Dobbiamo massimizzare questa varianza.
5/39
Varianza della prima componente: problema
- Tuttavia per trovare questo massimo abbiamo bisogno di
un vincolo, altrimenti otteniamo una varianza grande
quanto vogliamo. - Supponiamo di aver trovato un vettore a1 che ci fornisce il
massimo di Var(z1). Questa varianza potrebbe essere
ancora aumentata semplicemente prendendo ca1 (c > 1).
In questo modo otteniamo un numero di soluzioni infinito
per questo tipo di problema. - Quindi si deve introdurre un vincolo per a1, ad esempio:
afa1 = 1,
cioè il vettore a1 deve avere una norma unitaria (la somma
dei quadrati degli elementi deve essere 1).
6/39
Il moltiplicatore di Lagrange
- In ottimizzazione matematica, il metodo del moltiplicatore
di Lagrange é una strategia per trovare i massimi e i minimi
locali di una funzione, sulla base di alcuni vincoli. - Esempio:
(massimizzare f (x, y)
in modo tale che
g(x, y) = C. - Una nuova variabile ) viene introdotta (il moltiplicatore di
Lagrange, appunto) e il massimo e il minimo del cosiddetto
lagrangiano viene studiato:
L(x, y, X) = f(x, y) +x[g(x, y) - C].
7/39
Come si ottiene la prima componente nell'ACP
- Per trovare la prima componente principale dobbiamo
risolvere il seguente sistema dei moltiplicatori di Lagrange:
-
max Var (z1) = at Sa1
in modo tale che
afa1 = 1. - Il lagrangiano che deve essere massimizzato è:
L = afSa1 - X(afa1 - 1),
in cui X è il moltiplicatore di Lagrange.
8/39
Come si ottiene la prima componente nell'ACP
- Dato che stiamo affrontando un problema di
massimizzazione vincolata, possiamo trovare la soluzione
del sistema uguagliando la prima derivata parziale
(rispetto a a1) di L a zero:
SL
da1
= 2Sa1 - 2Xa1 = 2(S - XI)a1 = 0.
(1) - In altre parole, dobbiamo trovare a1 e ) in modo tale che
Sa1 = Xa1 - L'equazione (1) é un sistema lineare avente soluzione se e
solo se:
Det(S - XI) + 0.
(2)
9/39
Come si ottiene la prima componente nell'ACP
" Sappiamo dall'algebra matriciale che la soluzione
dell'equazione (2) é il vettore degli autovalori di S.
- Quindi, data una di queste soluzioni, per esempio X1, si ha:
Sa1 = X1a1,
(3)
cioé il vettore a1 é un autovettore (di norma 1) della
matrice S.
10/39
Come si ottiene la prima componente nell'ACP
- Quale autovalore scegliere?
- Se pre-moltiplichiamo entrambi i membri della (3) per af,
otteniamo:
afSa1 = Aafa1. - Ma poiché a1 é un vettore normalizzato, si ottiene:
afSa1 = Aafa] = >1 = Var(z1),
=1
e quindi scegliamo l'autovalore di S piu' alto .
11/39
Come si ottiene la seconda componente nell'ACP
- Il seguente ragionamento applicato alla seconda
componente puo' essere usato per ogni componente j
(j = 1,2, ... , p). - Bisogna considerare prima di tutto un'altra ipotesi: la
seconda componente z2 deve essere non correlata
(perpendicolare) alla prima componente z1. - Questo significa che, essendo la seconda componente
Z2 = Xa2, vogliamo avere z2 1 Z1. - Quindi, dobbiamo trovare il vettore a2 che massimizza
Var(Z2) soggetto a |a2 | = 1 e z2 1 z1.
12/39
Come si ottiene la seconda componente nell'ACP
- Quindi:
maxVar(z2) = a2Sa2
dato che:
afa2 = 1
az Sa1 = 0 (Questo significa che: z2 L z1). - Questa volta il lagrangiano é:
L(a2, A, v) = a2 Sa2 - X(a2a2 -1) - v(a2 Sa1). - Uguagliando a zero la derivata prima di questo lagrangiano
rispetto a a2 e ai due moltiplicatori ) e v si ottiene:
1
8a2
δ
δ
L(a2, A, V) = 2Sa2-2)a2-v(Sa1) = 0
& L(a2, A, v) = a2 a2 - 1 = 0
L(a2, A, v) = azSa1 = 0.
13/39
Come si ottiene la seconda componente nell'ACP
- Da quello che si è visto per la prima componente,
Sa1 = X1a1. - Questo quindi significa che a Sa1 = 0 implica Maza1 = 0
e, poiché )1 > 0, a2 a1 = 0. - Ora moltiplichiamo la prima equazione del sistema per af:
2 afSa2 -21 afa2 -vaf Sa1 = 0,
=0
=0
X1>0
da cui si ha che v = 0.
14/39
Come si ottiene la seconda componente nell'ACP
- Quindi la prima derivata in slide 13 diventa:
Sa2 = da2,
e, analogamente a quanto fatto per la prima componente:
Var(Z2) = 12, cioè la varianza della seconda componente
è uguale al secondo autovalore piu' grande della matrice S.
Da questo si ha Var(z1) > Var(z2) e, in generale:
Var(z1) > Var(Z2) > ... > Var(Zp).
15/39
Massimizzazione della varianza spiegata: razionale
- Perché si vuole che la prima componente abbia varianza
massima? - Vediamo perché con alcuni semplici esempi grafici.
- Supponiamo di avere i voti medi di alcuni studenti in
scienze (Sciences) e discipline umanistiche (Humanities):
Average science and humanities marks of 60 students
54
52
Humanities
50
48
46
46
48
50
52
54
Science
16/39
Massimizzazione della varianza spiegata: razionale
Average science and humanities marks of 60 students
54
52
Humanities
50
48
46
46
48
50
52
54
Science
Average science and humanities marks of 60 students
54
52
Humanities
50
48
46
46
48
50
52
54
Science
17/39
Massimizzazione della varianza spiegata: razionale
Domanda: se vogliamo confrontare il rendimento degli
studenti, quale voto dovrebbe essere un migliore fattore
discriminante? Scienze o discipline umanistiche?
- Risposta: Sicuramente scienze, poiché si ha la variazione
piu' grande per questa materia. - Questa e una situazione comune nell'analisi dei dati in cui
la direzione lungo la quale i dati variano di piu' é di
particolare importanza.
18/39
Massima varianza spiegata
Average science and humanities marks of 100 students
100
80
60
Humanities
40
20
0
0
20
40
60
80
100
Science
19/39
Massima varianza spiegata
- La direzione di massima variabilità in questo esempio è
lungo una ben definita retta. - Questo significa che dovremmo considerare la
combinazione lineare delle due votazioni (una sorta di
media pesata) per ottenere un risultato che tenga conto
delle due materie. - In questo semplice esempio la direzione di massima
variabilità/variazione è molto chiara. - Ma per la maggior parte delle situazioni reali
(specialmente con dimensioni molto grandi) questa
ispezione visuale non è adeguata e nemmeno possibile!
20/39
Massima varianza spiegata
Average science and humanities marks of 100 students
100
80
60
Humanities
40
20
0
L
0
20
40
60
80
100
Science
Average science and humanities marks of 100 students
100
80
1
Humanities
60
40
20
O
1
0
20
40
60
80
100
Science
21/39
Massima varianza spiegata: proiezioni
Average science and humanities marks of 100 students
80
70
60
Humanities
50
40
30
9
20
20
30
40
50
60
70
80
Science
22/39
Massima varianza spiegata: proiezioni
- La retta rossa è quella sulla quale vengono proiettati i punti
originali. - È la linea più vicina ai punti in termini di distanza euclidea
nella direzione della massima variabilità (varianza) dei dati. - Quindi, l'ACP cerca prima di trovare questa direzione e poi
la direzione ortogonale con meno varianza. - Con p variabili questo processo funziona trovando la
direzione con la varianza più alta, quindi la seconda, la
terza e così via. - Questa retta differisce dalla retta di regressione perché nel
metodo dei minimi quadrati la cerchiamo nella direzione
dell'asse y.
23/39
Retta di regressione vs. retta di proiezione
Average science and humanities marks of 100 students
80
Projection line (First component)
Regression line
70
60
Humanities
50
40
30
20
20
30
40
50
60
70
80
Science
24/39
Retta di regressione vs. retta di proiezione
- Cosa succede quando abbiamo dati "sparpagliati"?
Average science and humanities marks of 100 students
100
Projection line (First component)
" Regression line
.
80
.
60
Humanities
40
20
0
0
20
40
60
80
100
Science
25/39
Non hai trovato quello che cercavi?
Esplora altri argomenti nella Algor library o crea direttamente i tuoi materiali con l’AI.
