Módulo II: Introducción a la inferencia estadística paramétrica
Diapositivas sobre Introducción a la Inferencia Estadística. El Pdf, de nivel universitario, aborda la inferencia estadística paramétrica, estimadores puntuales y el análisis de varianza (ANOVA) para la comparación de múltiples muestras en Matemáticas.
Ver más17 páginas


Visualiza gratis el PDF completo
Regístrate para acceder al documento completo y transformarlo con la IA.
Vista previa
Introducción a la Inferencia Estadística Paramétrica
Se introducen algunas técnicas estadística útiles en inferencia estadística, esto es, traspaso de la información suministrada por la muestra a la población de interés. Por estar en inferencia paramétrica se asumirá que la variable de interés sigue una distribución normal. Es primordial tener claro que la utilización de todas estas técnicas están asumiendo que el diseño del experimento ha sido el adecuado (tamaños muestrales, encuestas, toma de la información, etc.), y por tanto, la muestra debería ser representativa de la población. Distinguiremos dos partes dependiendo del objetivo del estudio:
- Estimación (Interés en la predicción sobre valores de la población)
- Puntual
- Intervalos
- Contraste ó test de Hipótesis (Interés por aceptar o rechazar hipótesis planteadas sobre parámetros o variables de la población).
Inferencia Estadística: Estimación
Conceptos de Estimación
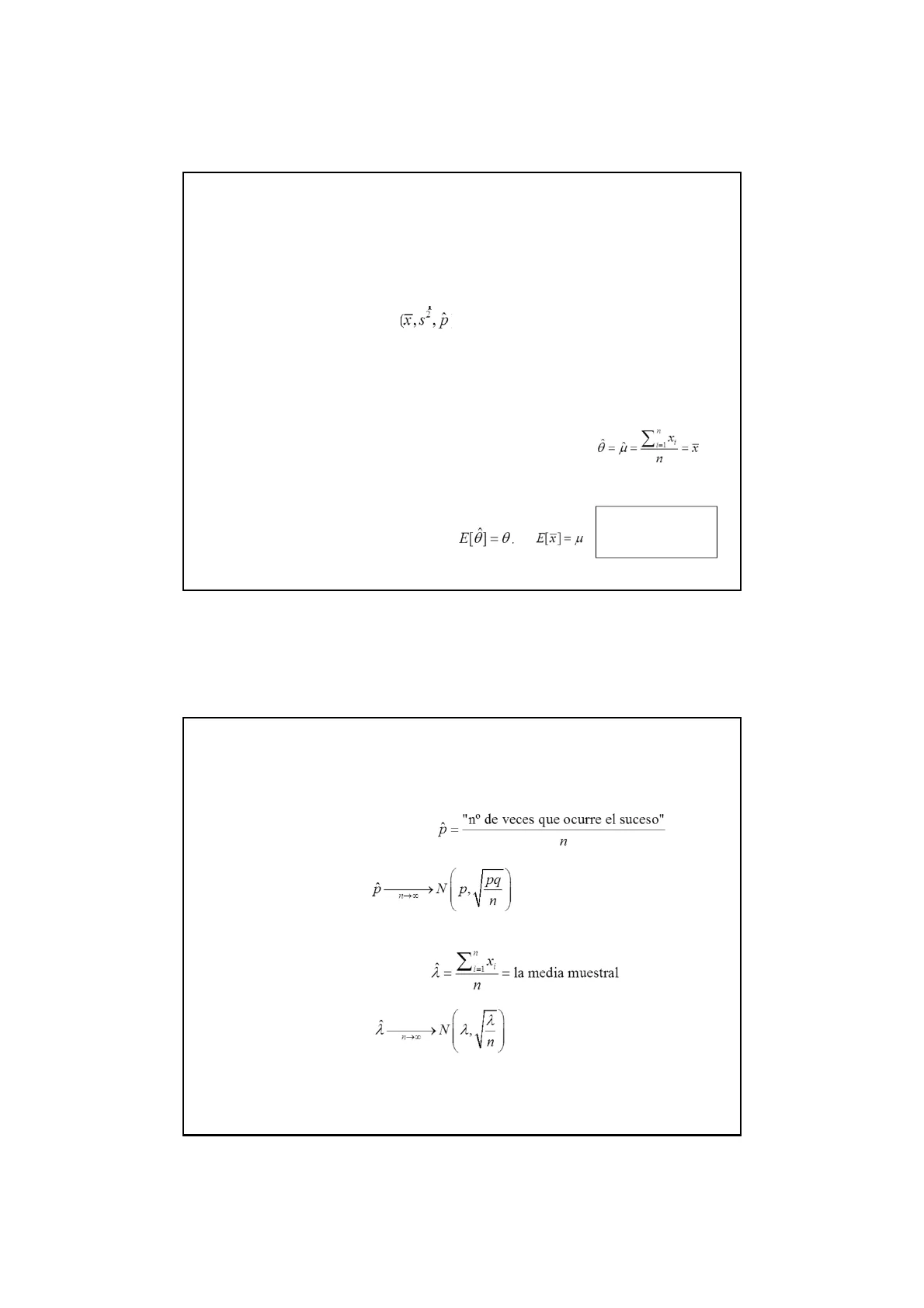
Se denomina estimador de un parámetro 0 (u, o, p, 2) generalmente poblacional, a la función o intervalo calculado a partir de la muestra que intenta obtener una predicción de dicho parámetro (x, s2, p ). El valor que se obtiene al sustituir en el estimador los valores de una muestra particular, se denomina estimación. Cuando el estimador es utilizado para obtener un valor aproximado único del parámetro poblacional diremos que se trata de una estimación puntual, y cuando se obtiene un intervalo de precisión de dicha estimación puntual hablaremos de estimación por intervalos. Ej. Un estimador para el parámetro poblacional 0 = µ, puede ser definido por 0 = û M n Un estimador, al ser función de los valores muestrales, será también una variable aleatoria (tendrá su media y su varianza). En general, se le exigen las siguientes propiedades:
- Ser insesgado o centrado, es decir, E[0] = 0. Ej. E[x] = u Nota: los estimadores que comentaremos cumplen ambas propiedades
- Mínima varianza (estimador eficiente).
Estimadores Puntuales
-
Distribución binomial, Bi(n, p). El estimador puntual de p es: "nº de veces que ocurre el suceso" n Además verifica que: p >N p, - pq n
-
Distribución de Poisson, P(2). El estimador puntual de 2 es: M = la media muestral n Además verifica que: Â >NA, 2 Vn
Estimación: Estimadores Puntuales
-
Distribución Normal, N(u, o). El estimador puntual de u es: M = x = la media muestral Se verifica que: â ~ N (u,on) ó de forma equivalente que: X-M ~ Z o Un El estimador puntual de o2 es: 62 = Die (x)-F)2 n-1 = s2 = la cuasivarianza muestral Además se verifica que: (n-1)52 ~ x1-1 y x-M s/ Vn =~ tn-1
Estimación: Estimación por Intervalos
Estamos interesados en dar un intervalo (a1, a2) de forma que contenga al parámetro a estimar 0 con una confianza (una probabilidad) de 1- « (siendo los valores más usuales 0.95, 0.90 y 0.99). Los extremos de este intervalo serán obtenidos a partir de los valores muestrales. P(a<0
Estimación por Intervalos: Aplicaciones
Utilizaremos tablas donde se suministran los distintos intervalos dependiendo de las características distribucionales de las variables empleadas. En general, serán identificados con la sigla I .* (* será un número). A continuación se comentan algunos casos particulares: I.01 Intervalo de confianza para la media u de una población normal con o conocida. Sabemos que X-µ ~ Z In y deseamos encontrar un intervalo (a1, a2) tal que P(a < < a2) =1-a entonces: 1-a=P(-za)
Estimación por Intervalos: Aplicaciones
I.02 Intervalo de confianza para la media u de una población normal con o desconocida. Sabemos que X-M_ s/ Jn In-1 y deseamos encontrar un intervalo (a1, a2) tal que P(a1 < < a2)=1-a entonces: 1-a=P(-tn-1,a/2 < s Jn X- M < t3-1,a/2 Lo que implica que el intervalo buscado sea L = P X- tn-10/2 In << X+tn-1,a/2 S I = X +tn-1,0/2] S In I.04 Intervalo de confianza para la varianza o2 de una población normal con media desconocida. Sabemos que (n-1) =~ X7 y deseamos encontrar un intervalo (a1, a2) tal que P(a) << < a2)=1-a entonces: 1- a = P ( Xn-1,1-a/2 < Xn-1
Estimación por Intervalos: Aplicaciones
I.06 e I.07 Intervalo de confianza para la diferencia de medias 141 -442 de dos poblaciones normales con varianzas desconocidas e iguales y distintas respectivamente. Ambos intervalos se construyen bajo la distribución t-student. Para decidir si utilizamos I.06 ó I.07 se debe realizar inicialmente el I.08 dedicado al intervalo de confianza para la razón de varianzas o /o2 de dos normales con medias desconocidas. Sabemos que: s2/02 Fm1-1,72-1 NOTA: FM-1,73-1,1-06 1 F Fm2-1,74-1,cc y deseamos encontrar un intervalo (a1, a2) tal que P(a <1/o2
Estimación por Intervalos: Aplicaciones
Ejemplo de Aplicación de Intervalos de Confianza
Ejemplo: Dos analistas determinaron los grados de dureza del agua de una ciudad. Obtener un intervalo de confianza al 90% de las diferencias de medias de las determinaciones de ambos analistas. Analista A: 0,46 0,62 0,37 0,40 0,44 0,58 0,48 0,53 Analista B: 0,82 0,61 0,89 0,51 0,33 0,48 0,23 0,25 0,67 0,88 Paso 1: Decidir que intervalo utilizar. Nos piden un intervalo para la diferencia de medias (I.05, I.06 ó I.07), pero no se conocen las varianzas poblacionales. Debemos utilizar I.06 ó I.07 dependiendo de si asumimos varianzas iguales o diferentes (a partir de la solución de I.08). Paso 2: Obtener la media, desviación típica y tamaño muestral de cada grupo. Analista A: XA = 0,485 SA = 0,0865 NA = 8 Analista B: XB = 0,515 SB = 0,2477 nB =10 Paso 3: Aplicamos I.08 con 1-a = 0,90, esto es, a/2=0,05. F7,9,0.05 =3,29 1 F-19,1-05 Fo 7 0.05 3,68 s3/53 =(0,036;0, 443) Como el 1 no pertenece al intervalo se asumen varianzas diferentes, lo que obliga a utilizar I.07. Paso 4: Aplicamos I.07 con 1-a = 0,90, esto es, u/2=0,05. (x1-xB) +,a/21 S SB =(-0,233; 0, 069) SA + f = SA/n +53/13 n ng n -1 n3 -1 Como el 0 pertenece al intervalo no podremos indicar que las mediciones con ambos analistas difieran entre sí. $12,0.05 = 1,782 2 5 2 /n, 'n 'A + =11,61~12 Vn. 1 =0,272 Fng-1,0g-1,c/2 F ng-1,ng-1,1-cx/2 A s2/82 /
Estimación por Intervalos: Aplicaciones Adicionales
I.09 Intervalo de confianza para la diferencia de medias de datos emparejados. Para realizar este intervalo se construirá la variable diferencia (di) y el intervalo será ya equivalente al caso I.02 sobre esa nueva variable. I.10 Intervalo de confianza para el parámetro p de una Binomial (estimar porcentajes). Podremos elegir entre tres posibilidades dependiendo de los valores de la estimación puntual y del número de datos. La última de ellas está basada en la transformación estabilizante de la varianza (arcoseno), y se puede usar sin restricciones (la calculadora debe estar en radianes) I.12 Intervalo de confianza para el parámetro 2 de una Poisson. Podremos elegir entre tres posibilidades dependiendo de los valores de la estimación puntual. La última de ellas está basada en la transformación estabilizante de la varianza (raíz cuadrada) y se puede usar sin restricciones.
Estimación: Tamaños Muestrales
La idea general es que deseamos estimar el parámetro 0 por medio de Ô con una precisión de d unidades (o en ocasiones, dada en función de ko ) y con un nivel de confianza de 1-a. Esto es, P(|0-0|
Estimación: Tamaños Muestrales
Cálculo del Tamaño Muestral para Proporción Binomial
Cálculo del tamaño muestral cuando se desea estimar la proporción de una binomial. Teniendo en cuenta que la varianza de pes p(1- p)/ nse tiene (I.10) que : n=(EL ) (1-P) El problema de esta fórmula es que estamos interesados en estimar el valor de p, y el tamaño muestral depende de él, aunque la función p(1-p) está acotada. • Si no existe información sobre p, sustituir en la ecuación anterior p por 1/2. p(1-p) 1/4 0 1/2 1 P b) Si se sabe que p E [a, b] entonces sustituir en la ecuación anterior p por el valor más próximo a 1/2 dentro de dicho intervalo. Ej. Si nos indican que se sabe que p no superará el 30%, es decir, p = [0,.30], sustituiremos p por .3.
Cálculo del Tamaño Muestral para Parámetro Poisson
Cálculo del tamaño muestral cuando se desea estimar el parámetro 2 de una Poisson. Teniendo en cuenta que la varianza de 2 = x es 2 / n se tiene (I.12) que : Existe el mismo problema que en el caso binomial, pues depende del parámetro que se desea estimar. a Si se sabe que 2 no superará un cierto valor, sustituir en la fórmula 2 por ese valor. b) En otro caso, se debe trabajar con muestras piloto, comprobando que se dé la precisión exigida, calculando intervalos de confianza.
Inferencia Estadística: Contraste de Hipótesis
El contraste de hipótesis constituye la segunda parte de la Inferencia Estadística. En él trataremos de dar algunas técnicas que nos permitan afirmar o rechazar hipótesis sobre parámetros de las variables a estudio (u, o, 2, normalidad, independencia, ... ) Dentro de este módulo abordaremos técnicas englobadas en lo que se conoce como estadística paramétrica (suponemos que la variable a estudio sigue la distribución normal).
Conceptos de Contraste de Hipótesis
· Hipótesis nula (Ho): hipótesis que se somete a comprobación, y suele ser la que se considera cierta mientras no se demuestre lo contrario. · Hipótesis alternativa (H1 ó Ha): hipótesis que se plantea y que se aceptará en caso de rechazar H0. En general, H1 será la negación de H0. Ej .: Un fabricante indica que cada envase contiene 100 unidades del producto. Se sospecha que esto puede ser falso, y por ello se realiza un muestreo para intentar demostrarlo. Asumamos que X ="cantidad de unidades de producto por envase" ~ N(u,o). El contraste podemos plantearlo como: [Ho:p=100 H : ##100
¿Non has encontrado lo que buscabas?
Explora otros temas en la Algor library o crea directamente tus materiales con la IA.
