Stime e incertezza: errore sperimentale e analisi dei dati
Documento dall'Università su Stime ed Incertezza. Il Pdf esplora i concetti di stime e incertezza, focalizzandosi sull'errore sperimentale e la sua quantificazione, con esempi pratici e simulazioni Monte Carlo per la Matematica a livello universitario.
Mostra di più20 pagine


Visualizza gratis il Pdf completo
Registrati per accedere all’intero documento e trasformarlo con l’AI.
Anteprima
Stime e Incertezza
Nel capitolo precedente abbiamo visto che:
- I fenomeni biologici seguono una legge di natura (verità 'vera'), che ne costituisce il meccanismo deterministico fondamentale. Questa legge di natura produce un risultato atteso YE.
- Quando si organizza un esperimento, i soggetti sperimentali obbedisco- no a questo meccanismo di fondo, al quale tuttavia si sovrappongono molto altri elementi di 'confusione,' altamente incontrollabili, che vanno sotto il nome di errore sperimentale.
- L'osservazione sperimentale è quindi un'immagine confusa della verità vera (Yo # YE) e, soprattutto, essa tende ad essere diversa per ogni sforzo di campionamento.
- Compito del ricercatore è comprendere come sia la verità 'vera,' sepa- rata dal 'rumore di fondo' generato dall'errore sperimentale.
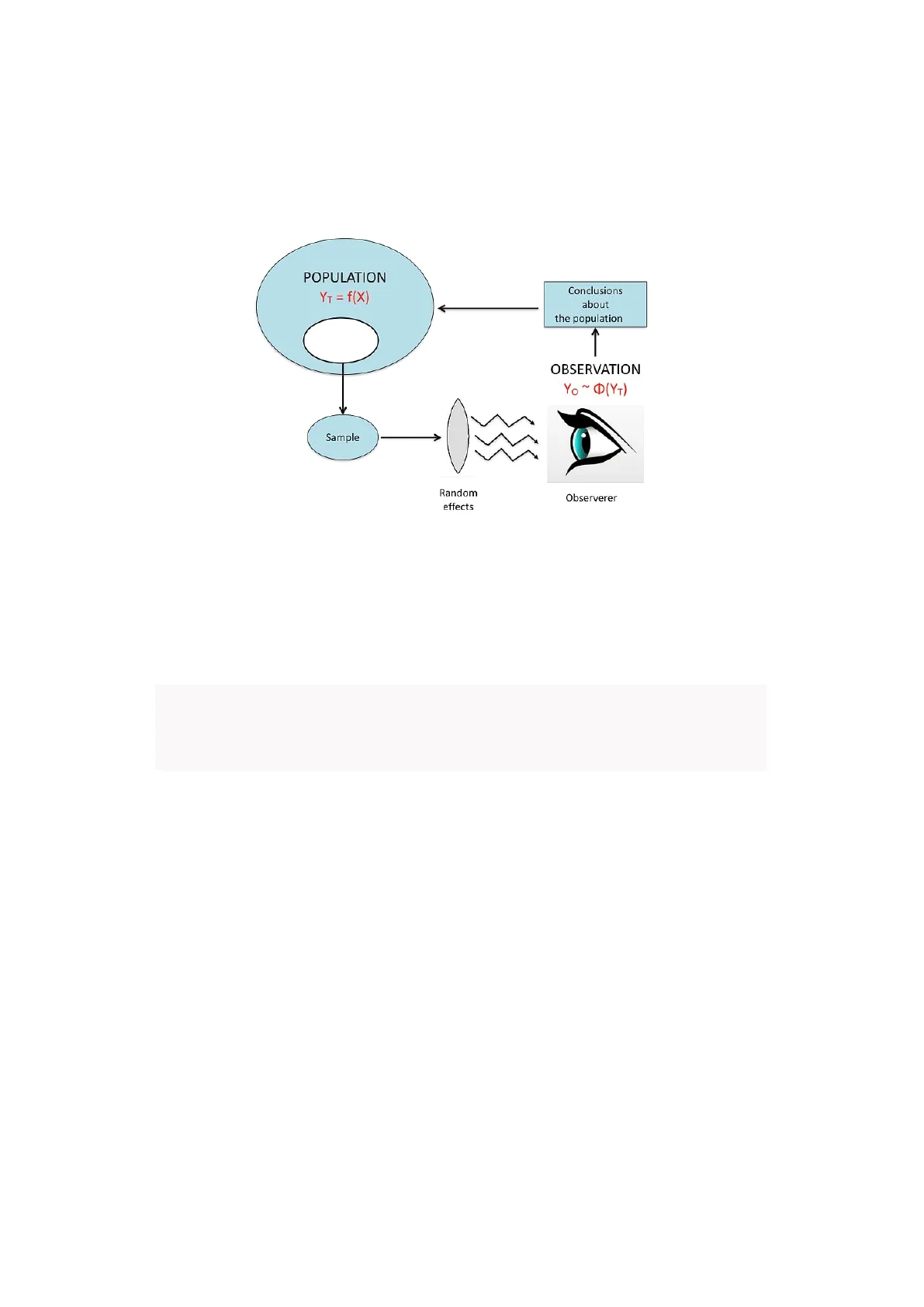
Questo dualismo tra verità 'vera' (inconoscibile) e verità sperimentale (esplo- rabile tramite un esperimento opportunamente pianificato) è l'aspetto cen- trale di tutta la biometria ed è schematizzato nella figura
5.1
Esempio: Soluzione Erbicida
Nel capitolo precedente, abbiamo introdotto un esempio relativo ad un pozzo inquinato da un erbicida a concentrazione pari a 120 mg/L, che viene misu- rata tramite un gascromatografo. Questo strumento di misura, unitamente a tutte le altre fonti ignote di errore, produce un coefficiente di variabilità del 10% (corrispondente ad una deviazione standard di 12 mg/L). Abbiamo
9192 CAPITOLO 5. STIME ED INCERTEZZA POPULATION YT = f(X) Conclusions about the population OBSERVATION Υo ~ Φ(Υ) Sample Random effects Observerer
Figura 5.1: Osservazioni sperimentali e meccanismi perturbativi anche visto che, se immaginiamo di fare le analisi in triplicato, come usua- le per questo tipo di lavori, i risultati di questo esperimento possono essere simulati ricorrendo ad un generatore di numeri casuali:
set . seed (1234) Y <- rnorm(3, 120, 12) Y ## [1] 105.5152 123.3292 133.0133
Ricordiamo che i numeri casuali, in quanto tali, dovrebbero essere diversi ogni volta che li estraiamo, anche se, utilizzando la funzione set.seed(), è possibile indurre l'algoritmo a produrre sempre gli stessi valori, in modo che i calcoli di questo capitolo siano riproducibili.
Analisi dei Dati: Stima dei Parametri
A questo punto mettiamoci in una situazione reale e, di conseguenza, di- mentichiamo di conoscere che la concentrazione ignota è pari a 120 mg/L e che o = 12. Ipotizziamo quindi che le nostre osservazioni sperimentali siano generate da un modello del tipo:
Yi = " + E;93 CAPITOLO 5. STIME ED INCERTEZZA
con:
E; ~ N(0, 0)
Nelle due equazioni sovrastanti, gli elementi incogniti sono p e o. Guardando il campione, le nostre migliori stime per queste due quantità, che chiameremo rispettivamente m ed s, sono pari rispettivamente alla media e alla deviazione standard del campione.
m <- mean (Y) s <- sd(Y) m; s [1] 120.6192 ## [1] 13.9479
Questo processo con il quale assegniamo alla popolazione le caratteristiche del campione prende il nome di stima puntuale dei parametri. Vediamo ancora una volta che l'osservazione sperimentale non coincide con la verità 'vera' (m + u e s ± o), ma non siamo molto distanti, considerando il 10% di variabilità dello strumento di analisi. Tuttavia, visto che dobbiamo trarre conclusioni che riguardano la popolazione e non il campione, è giustificato da parte nostra un atteggiamento prudenziale: prima di dire che la concen- trazione erbicida nella soluzione è pari 120.6192187, dobbiamo chiederci: che cosa succederebbe se ripetessimo l'esperimento molte altre volte?
La 'Sampling Distribution'
In questo caso l'esperimento è solo 'elettronico' e possiamo quindi ripeterlo un numero anche molto elevato di volte, seguendo questa procedura:
- Ripetiamo l'estrazione precedente per 100'000 volte (ripetiamo l'analisi chimica per 100'000 volte, sempre con tre repliche)
- Otteniamo 100'000 medie
- Calcoliamo la media delle medie e la deviazione standard delle medie
# Simulazione MONTE CARLO - Esempio 1 set . seed (1234) result <- rep(0, 100000) for (i in 1:100000) { sample <- rnorm(3, 120, 12) result [i] <- mean (sample) }94 CAPITOLO 5. STIME ED INCERTEZZA
mean (result) ## [1] 120.0341 sd(result) ## [1] 6.939063
In sostanza, la simulazione Monte Carlo ci consente di fare quello che do- vremmo sempre fare, cioè ripetere l'esperimento un numero di volte molto elevato, anche se finito (un numero infinito è chiaramente impossibile!). A questo punto abbiamo in mano una popolazione di medie, che viene detta sampling distribution, un 'oggetto' abbastanza 'teorico,' ma fondamenta- le per la statistica frequentista, perché caratterizza la variabilità dei risultati di un esperimento, e quindi la sua riproducibilità.
Notiamo che:
- La media delle medie è praticamente coincidente con p, la verità 'vera.' Ciò conferma che l'unico modo di ottenere risultati totalmente precisi è ripetere infinite volte l'esperimento;
- La deviazione standard delle medie è pari a 6.939063. Questo valore prende il nome di errore standard della media (SEM).
Esploriamo meglio la sampling distribution. Con R possiamo provare a discretizzarla e a riportarla su di un grafico a barre (figura 5.2 ).
L'Errore Standard
La sampling distribution che abbiamo ottenuto con la simulazione Monte Carlo è puramente empirica. Sarebbe interessante capire con più esattezza se esista una funzione di densità che permetta di descriverla con esattezza. In effetti, il grafico precedente mostra che la sampling distribution assomi- glia molto ad una distribuzione normale, con media pari a 120 e deviazione standard pari all'errore standard.
Formalmente, il problema si può risolvere grazie alla legge di propagazione degli errori, che stabilisce tre importanti elementi:
- Se ho due variabili normalmente distribuite e le sommo tra di loro, la variabile risultante è ancora normale. Se ho una variabile normalmente distribuita e la moltiplico per una costante, la variabile risultante è ancora normale.
- Per variabili indipendenti, la varianza della somma è uguale alla somma delle varianze.95 CAPITOLO 5. STIME ED INCERTEZZA
0.04 Density 0.02 0.00 80 100 120 140 160 m
Figura 5.2: Sampling distribution empirica e teorica
- La varianza del prodotto di una variabile per una costante k è pari alla varianza della variabile originale moltiplicata per k2.
Consideriamo che, quando preleviamo alcuni individui da una popolazione, ognuno di essi porta con sé una sua componente di incertezza, che egli 'ere- dita' dalla popolazione di cui fa parte. In questo caso, la popolazione ha una varianza pari a 122 = 144 e quindi ognuno dei tre soggetti campionati eredita tale varianza. Quando calcolo la media di tre osservazioni, in prima battuta io le sommo. A questo punto, dato che si tratta di osservazioni indipendenti, la propagazione degli errori (punto 2) ci dice che la varianza della somma è uguale a 144 x 3 = 432.
Dopo aver sommato, il calcolo della media richiede che il risultato venga diviso per 3. La legge di propagazione degli errori (punto 3) ci dice quindi che la varianza viene divisa per 32 = 9. Insomma la popolazione delle medie è normale (punto 1), ha media pari a 120 e varianza pari a 432/9 = 48 e, di conseguenza, deviazione standard pari a v48 = 6.928, cioè 12/V3. In generale, l'errore standard di una media è:
Om = In Vn96 CAPITOLO 5. STIME ED INCERTEZZA
dove n è la dimensione del campione.
Stima per Intervallo
Che cosa ci insegna questo esperimento? Ci insegna che, se prendiamo una distribuzione normale con media p e deviazione standard o e cominciamo ad estrarre campioni, le medie dei campioni sono variabili, secondo una distribu- zione normale con media p e deviazione standard o/Vn. Questo concetto è interessante e può essere utilizzato per caratterizzare l'incertezza dei risultati di un esperimento. Riassumiamo:
- Abbiamo fatto un esperimento con tre repliche campionando da una distribuzione normale incognita.
- Abbiamo ottenuto i tre valori 105.5152, 123.3292 e 133.0133.
- In base alle osservazioni in nostro possesso, m = 120.6192 mg/L, e, considerando che la cosa più probabile è che la media del campione sia uguale a quella della popolazione, concludiamo che p = m.
- Dobbiamo adottare un atteggiamento prudenziale in relazione alla me- dia, dato che non sappiamo il valore vero di p. Sappiamo che le me- die campionarie producono una sampling distribution caratterizzata da una deviazione standard pari a o/ Vn. Non conoscendo o, utilizziamo la sua miglior stima s e concludiamo che ES = 13.95/V3 = 8.05.
- Concludiamo quindi che p è pari a 120.6192 ± 8.053.
Abbiamo caratterizzato l'incertezza del risultato attraverso un intervallo di valori (stima per intervallo).
L'Intervallo di Confidenza
La stima per intervallo fu uno degli interessi di ricerca del matematico polacco Jerzy Neyman (1894-1981), che definì la teoria degli intervalli di confidenza, ancora molto seguita anche ai giorni nostri. Partendo dal presupposto che le medie campionarie sono distribuite normalmente con media p e deviazione standard o/ Vn, è possibile calcolare la probabilità « di trovare un campione la cui media era contenuta in un certo intervallo. Prendiamo, ad esempio, la nostra popolazione iniziale, con p = 120 e o = 12. È facile vedere che c'è il 68% circa di probabilità di ottenere un campione con media inclusa nell'intervallo 120 ± 12a/V3:97 CAPITOLO 5. STIME ED INCERTEZZA
pnorm(120 + 12/sqrt(3), 120, 12/sqrt(3)) - pnorm(120 - 12/sqrt(3), 120, 12/sqrt(3)) ## [1] 0.6826895
Aumentando l'ampiezza dell'intervallo, è possibile aumentare la probabilità di campionare al suo interno. Ad esempio, se moltiplichiamo l'errore stan- dard per due, la probabilità di ottenere un campione con una media inclusa nell'intervallo 120 ± 2 × 12/13 supera (di poco) il 95%:
mult <- 2 pnorm(120 + mult * 12/sqrt(3), 120, 12/sqrt(3)) - pnorm(120 - mult * 12/sqrt(3), 120, 12/sqrt(3)) ## [1] 0.9544997
È possibile ottenere esattamente una probabilità del 95% utilizzando come moltiplicatore dell'errore standard il 97.5-esimo quantile della distribuzione normale standardizzataL
mult <- qnorm(0.975, mean = 0, sd = 1) pnorm(120 + mult * 12/sqrt(3), 120, 12/sqrt(3)) - pnorm(120 - mult * 12/sqrt(3), 120, 12/sqrt(3)) ## [1] 0.95
Se approssimiamo il 97.5-esimo quantile della distribuzione normale standar- dizzata alla seconda cifra decimale (per semplicità), possiamo scrivere:
P M- 1.96 x Sm _ M+ 1.96 x = 0.95 L
Per il nostro esempio possiamo concludere che la probabilità di estrarre un campione di acqua dal nostro pozzo inquinato, analizzarlo in triplicato ed ottenere una concentrazione media all'interno dell'intervallo p± 1.96 x o / Vn è del 95%.
Con semplici passaggi algebrici, possiamo ottenere l'intervallo di confiden- za:
P m - 1.96 x SH Cm + 1.96 X ] = 0.05 1 Tra tutte le distribuzioni normali, ce n'è una particolare, che ha media 0 e deviazione standard 1. Questa si chiama distribuzione normale standardizzata
Non hai trovato quello che cercavi?
Esplora altri argomenti nella Algor library o crea direttamente i tuoi materiali con l’AI.
